Train_Segmenter Class Reference
This class can 'train' new speaker clusters. One could call determining the clusters training because the phone (SIL) training procedures are used. But in fact, training is done on the target data (not on a training set), so it is not really training but processing. See our Spring 2006 NIST Rich Transcription Speaker Diarization paper for more information. This is ment to be the most simple form of the HMM-based merging diarization method. Overloaded classes may be created for testing new algorithms. More...
Public Member Functions | |
| Train_Segmenter (FeaturePool *fp, int sID_train, int sID_decode, const char *name, int nrMerges, int minClusters, int maxClusters, bool widen, const char *nonMergeableModels) | |
| virtual | ~Train_Segmenter () |
| void | train (int maxClusters, char *label, char *tempStr, char *feaPosteriors, int segID_cheat=-1) |
| int | getSegmentation () const |
| void | storeClusters (FILE *outFile, char *outputName) |
| void | loadClusters (FILE *inFile) |
Protected Member Functions | |
| double | trainIteration (int nrIterations) |
| double | trainClusters (int nrG=-1) |
| bool | mergeClusters (int maxClusters, bool smallestWins, bool actuallyMerge) |
| void | createInitialModels (int segAmount, char *outputName=NULL) |
| void | createOverlapTree (int min) |
| virtual void | startMergeIteration () |
| virtual void | getMergeModelScore (int model1, int model2, double *mergeScore) |
| virtual bool | proceedMerge (int model1, int model2, int method) |
| virtual void | mergeModels (int model1, int model2) |
| virtual void | trainModel (int model, int nrG, double *trainPRes) |
| void | getOverlap (FILE *file) |
| void | writePosteriors (char *fileName) |
Protected Attributes | |
| char | outputFileName [2000] |
| char | label [200] |
| int | sadID_train |
| int | sadID_decode |
| int | segID |
| int | segID_decode |
| int | segID_cheat |
| TrainPhoneModel ** | trainCluster |
| TrainPhoneModel ** | scoreCluster |
| int | nrScoreClusters |
| Vector ** | distanceVect |
| bool * | mergeable |
| int | nrNonMergeModels |
| double * | clusterScore |
| int * | clusterSize |
| int | cheatSpk1 |
| int | cheatSpk2 |
| int | numberOfMerges |
| int * | compareClusters |
| PhoneModel * | vtlnModel |
| int | fastMerge |
| bool | prepareForASR |
| int | maxDataPoints |
| bool | detectOverlap |
| int | nrMergeIterations |
| double | bic_meanoffset [10] |
| TrainPhoneModel * | trcl |
Detailed Description
This class can 'train' new speaker clusters. One could call determining the clusters training because the phone (SIL) training procedures are used. But in fact, training is done on the target data (not on a training set), so it is not really training but processing. See our Spring 2006 NIST Rich Transcription Speaker Diarization paper for more information. This is ment to be the most simple form of the HMM-based merging diarization method. Overloaded classes may be created for testing new algorithms.Constructor & Destructor Documentation
| Train_Segmenter::Train_Segmenter | ( | FeaturePool * | fp, | |
| int | sID_train, | |||
| int | sID_decode, | |||
| const char * | name, | |||
| int | nrMerges, | |||
| int | minClusters, | |||
| int | maxClusters, | |||
| bool | widen, | |||
| const char * | nonMergeableModels | |||
| ) |
This constructor will initialise a LexicalTree topology with (hopefully) too many clusters.
References bic_meanoffset, FeaturePool::claimSegmentationID(), cluster_thread, cluster_threadMayStart, cluster_threadRunning, clusterScore, clusterSize, compareClusters, createOverlapTree(), detectOverlap, distanceVect, TrainPhoneModel::doNotuseBordersForTraining(), fastMerge, Segmenter::featurePool, WriteFileLittleBigEndian::freadEndianSafe(), FeaturePool::getClusterLength(), FeaturePool::getStreamInfo(), FeaturePool::getVectorSize(), Thread_Train_Data_Cluster::id, LexicalTree::languageModel, maxDataPoints, mergeable, nrMergeIterations, nrNonMergeModels, Segmenter::numberOfClusters, numberOfMerges, LexicalTree::numberOfPhones, LexicalTree::numberOfWords, LexicalTree::overwriteWeightPars(), LexicalTree::phoneModels, prepareForASR, TrainPhoneModel::readModel(), sadID_decode, sadID_train, segID, segID_decode, Segmenter::setFeaturePool(), TrainPhoneModel::setTrainingData(), thread_train_cluster(), trainCluster, trcl, and LexicalTree::vocabulary.
| Train_Segmenter::~Train_Segmenter | ( | ) | [virtual] |
The destructor will delete all claimed memory (the clusters)
References clusterScore, compareClusters, Segmenter::featurePool, FeaturePool::freeSegmentationID(), LexicalTree::numberOfPhones, LexicalTree::phoneModels, segID, and trainCluster.

Member Function Documentation
| void Train_Segmenter::createInitialModels | ( | int | segAmount, | |
| char * | outputName = NULL | |||
| ) | [protected] |
We have done training, let's start merging!
References Segmenter::featurePool, FeaturePool::getClusterLength(), LexicalTree::numberOfWords, sadID_train, segID, trainClusters(), and trainIteration().
Referenced by train().
| void Train_Segmenter::createOverlapTree | ( | int | min | ) | [protected] |
References Segmenter::createLexicalTree(), LexicalTree::numberOfPhones, LexicalTree::numberOfWords, and trainCluster.
Referenced by getOverlap(), loadClusters(), train(), Train_Segmenter(), trainIteration(), and trainModel().
| void Train_Segmenter::getMergeModelScore | ( | int | model1, | |
| int | model2, | |||
| double * | mergeScore | |||
| ) | [protected, virtual] |
Merges two single models and calculates the total score..
References Segmenter::featurePool, FeaturePool::getStreamInfo(), TrainPhoneModel::getTrainSilP(), FeaturePoolInfo::numberOfChannels, FeaturePool::resetStreamWeights(), segID, FeaturePool::setStreamWeights(), TrainPhoneModel::setTrainingData(), TrainPhoneModel::train(), trainCluster, and weights.
Referenced by mergeClusters().
| void Train_Segmenter::getOverlap | ( | FILE * | file | ) | [protected] |
- Todo:
- Docs
References FeaturePool::addSegment(), FeaturePool::claimSegmentationID(), clusterScore, clusterSize, Segmenter::createLexicalTree(), createOverlapTree(), SegmentationAdmin::curSeg, TrainPhoneModel::doNotuseBordersForTraining(), Segmenter::featurePool, SegmentationList::firstFrame, FeaturePool::freeSegmentationID(), FeaturePool::getClusterLength(), FeaturePool::getCurSegmentLen(), FeaturePool::getCurSegmentStart(), FeaturePool::getFirstVectorFirstSegment(), FeaturePool::getFirstVectorNextSegment(), PhoneModel::getLogPDFProbability(), FeaturePool::getNextVector(), FeaturePool::getSegmentID(), FeaturePool::getStreamInfo(), TrainPhoneModel::getTrainSilP(), FeaturePool::getVectorSize(), SegmentationList::ID, label, SegmentationList::lastFrame, mergeClusters(), SegmentationList::next, LexicalTree::numberOfWords, outputFileName, SegmentationAdmin::prevSeg, sadID_decode, sadID_train, segID, FeaturePool::segmentationCreateOverlap(), Segmenter::segmentFeaturePool(), TrainPhoneModel::setTrainingData(), TrainPhoneModel::train(), trainCluster, trainClusters(), LexicalTree::vocabulary, PhoneModel::writeModel(), and FeaturePool::writeRTTM().
Referenced by train().
| int Train_Segmenter::getSegmentation | ( | ) | const [inline] |
References segID_decode.
| void Train_Segmenter::loadClusters | ( | FILE * | inFile | ) |
This method will load the trained clusters from inFile.
References FeaturePool::claimSegmentationID(), createOverlapTree(), TrainPhoneModel::doNotuseBordersForTraining(), Segmenter::featurePool, WriteFileLittleBigEndian::freadEndianSafe(), FeaturePool::freeSegmentationID(), FeaturePool::getStreamInfo(), FeaturePool::getVectorSize(), Segmenter::numberOfClusters, LexicalTree::numberOfWords, TrainPhoneModel::readModel(), sadID_train, segID, segID_cheat, segID_decode, FeaturePool::segmentationIntersection(), Segmenter::segmentFeaturePool(), TrainPhoneModel::setTrainingData(), and trainCluster.
Referenced by train().
| bool Train_Segmenter::mergeClusters | ( | int | maxClusters, | |
| bool | smallestWins, | |||
| bool | actuallyMerge | |||
| ) | [protected] |
This method reduces the network with a single state (cluster).
References bic_meanoffset, cheatSpk1, cheatSpk2, fastMerge, Segmenter::featurePool, FeaturePool::getClusterLength(), Gaussian::getMean(), getMergeModelScore(), FeaturePool::getStreamInfo(), FeaturePool::getStreamWeight(), Vector::getValue(), Gaussian::getVariance(), globalIt, label, mergeable, mergeModels(), nrMergeIterations, FeaturePoolInfo::numberOfChannels, Segmenter::numberOfClusters, numberOfMerges, LexicalTree::numberOfWords, outputFileName, segID, FeaturePool::setStreamWeights(), Vector::setValue(), startMergeIteration(), Gaussian::train(), trainCluster, and Gaussian::trainFinish().
Referenced by getOverlap(), and train().
| void Train_Segmenter::mergeModels | ( | int | model1, | |
| int | model2 | |||
| ) | [protected, virtual] |
Merges two single models (over loaded by Adapt_Segmenter)
Reimplemented in Adapt_Segmenter.
References FeaturePool::claimSegmentationID(), Segmenter::featurePool, FeaturePool::freeSegmentationID(), globalIt, label, FeaturePool::mergeLabels(), Segmenter::numberOfClusters, outputFileName, segID, segID_cheat, segID_decode, FeaturePool::segmentationIntersection(), TrainPhoneModel::setTrainingData(), TrainPhoneModel::train(), and trainCluster.
Referenced by mergeClusters().
| bool Train_Segmenter::proceedMerge | ( | int | model1, | |
| int | model2, | |||
| int | method | |||
| ) | [protected, virtual] |
We have decided on two merge candidates. Now determine if we should actually do it, or just stop.
Reimplemented in Adapt_Segmenter.
| void Train_Segmenter::startMergeIteration | ( | ) | [protected, virtual] |
Before we check which model to merge, we do some preparations in this method.
Reimplemented in Adapt_Segmenter.
References compareClusters, and LexicalTree::numberOfWords.
Referenced by mergeClusters().
| void Train_Segmenter::storeClusters | ( | FILE * | outFile, | |
| char * | outputName | |||
| ) |
This method will store the trained clusters to outFile.
References FeaturePool::claimSegmentationID(), Segmenter::featurePool, FeaturePool::getClusterLength(), FeaturePool::getNumberOfSpeakers(), FeaturePool::getSpeakerID(), FeaturePool::getVectorSize(), Segmenter::numberOfClusters, FeaturePool::readRTTM(), sadID_decode, trainCluster, and PhoneModel::writeModel().

| void Train_Segmenter::train | ( | int | maxClusters, | |
| char * | label, | |||
| char * | tempStr, | |||
| char * | feaPosteriors, | |||
| int | segID_cheat = -1 | |||
| ) |
References FeaturePool::addSegment(), FeaturePool::claimSegmentationID(), cluster_threadRunning, condition_cluster_mutexDone, condition_cluster_threadDone, createInitialModels(), Segmenter::createLexicalTree(), createOverlapTree(), detectOverlap, Segmenter::featurePool, FeaturePool::freeSegmentationID(), FeaturePool::getClusterLength(), FeaturePool::getCurSegmentLen(), FeaturePool::getCurSegmentStart(), FeaturePool::getFirstVectorFirstSegment(), FeaturePool::getFirstVectorNextSegment(), getOverlap(), FeaturePool::getStreamInfo(), globalIt, LexicalTree::initialiseSystem(), label, loadClusters(), loadedOverlapAM, mergeClusters(), nrNonMergeModels, FeaturePoolInfo::numberOfChannels, Segmenter::numberOfClusters, LexicalTree::numberOfWords, outputFileName, prepareForASR, FeaturePool::resetSegmentation(), sadID_decode, sadID_train, segID, segID_cheat, segID_decode, SEGMENT_INITIAL_DATA_SEGMENTS, FeaturePool::segmentationCreateOverlap(), FeaturePool::segmentationWiden(), Segmenter::segmentFeaturePool(), trainCluster, trainIteration(), trainModel(), FeaturePoolInfo::weight, writePosteriors(), and FeaturePool::writeRTTM().
Referenced by Shout_Cluster::Shout_Cluster().
| double Train_Segmenter::trainClusters | ( | int | nrG = -1 |
) | [protected] |
The training iterations are performed by this method.
References cluster_threadRunning, clusterScore, condition_cluster_mutexDone, condition_cluster_threadDone, TrainPhoneModel::maxNrOfGaussians(), mergeable, LexicalTree::numberOfWords, trainCluster, and trainModel().
Referenced by createInitialModels(), getOverlap(), and trainIteration().
| double Train_Segmenter::trainIteration | ( | int | nrIterations | ) | [protected] |
The main method of a train iteration:
- align the data using Segmenter::segmentFeaturePool()
- train the clusters (states) with trainClusters()
References LanguageModel_Segmenter::addPenalty(), FeaturePool::claimSegmentationID(), createOverlapTree(), Segmenter::featurePool, LanguageModel_Segmenter::finishModel(), FeaturePool::freeSegmentationID(), FeaturePool::getFirstVectorFirstSegment(), FeaturePool::getFirstVectorNextSegment(), FeaturePool::getSegmentID(), LexicalTree::languageModel, Segmenter::numberOfClusters, LexicalTree::numberOfWords, sadID_train, segID, segID_cheat, segID_decode, FeaturePool::segmentationIntersection(), Segmenter::segmentFeaturePool(), TrainPhoneModel::setTrainingData(), trainCluster, trainClusters(), and LanguageModel_Segmenter::transferTo().
Referenced by createInitialModels(), and train().
| void Train_Segmenter::trainModel | ( | int | model, | |
| int | nrG, | |||
| double * | trainPRes | |||
| ) | [protected, virtual] |
Trains a single model with nrG gaussians (over loaded by Adapt_Segmenter)
References cluster_threadMayStart, cluster_threadRunning, condition_cluster_mutexDone, condition_cluster_mutexStart, condition_cluster_threadDone, condition_cluster_threadStart, createOverlapTree(), Segmenter::discrTrain, Segmenter::discrTrainMask, FeaturePool::doSegmentsExist(), Segmenter::featurePool, TrainPhoneModel::getTrainSilP(), mergeable, Thread_Train_Data_Cluster::model, Thread_Train_Data_Cluster::nr, Thread_Train_Data_Cluster::segid, segID, TrainPhoneModel::setTrainingData(), TrainPhoneModel::train(), trainCluster, and Thread_Train_Data_Cluster::trainPRes.
Referenced by train(), and trainClusters().
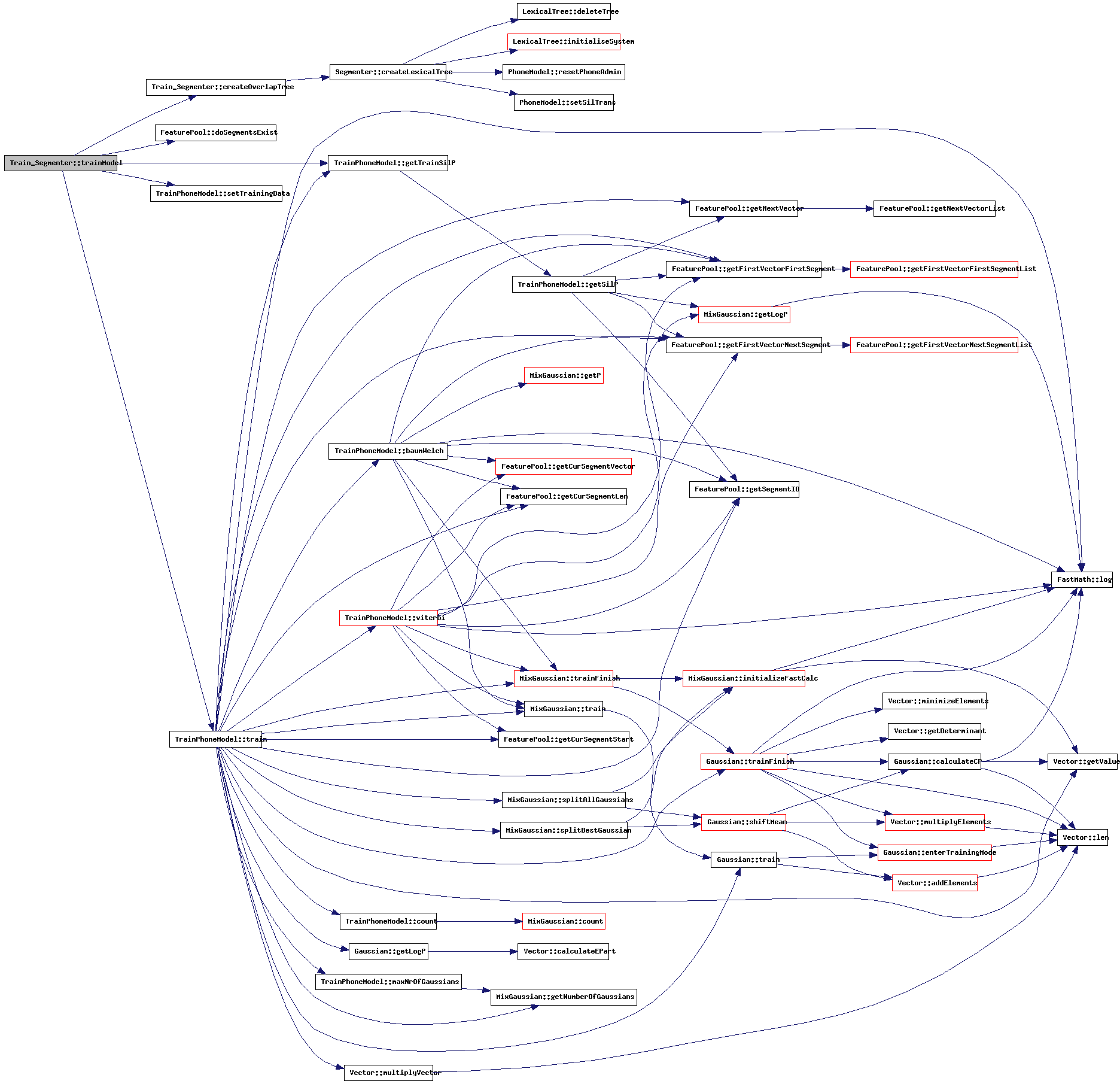
| void Train_Segmenter::writePosteriors | ( | char * | fileName | ) | [protected] |
- Todo:
- Docs
References Segmenter::featurePool, PhoneModel::getPDFProbability(), FeaturePool::getPoolLength(), FeaturePool::getVector(), LexicalTree::numberOfWords, and trainCluster.
Referenced by train().

Member Data Documentation
double Train_Segmenter::bic_meanoffset[10] [protected] |
Referenced by mergeClusters(), and Train_Segmenter().
int Train_Segmenter::cheatSpk1 [protected] |
Referenced by mergeClusters().
int Train_Segmenter::cheatSpk2 [protected] |
Referenced by mergeClusters().
double* Train_Segmenter::clusterScore [protected] |
Referenced by getOverlap(), Train_Segmenter(), trainClusters(), and ~Train_Segmenter().
int* Train_Segmenter::clusterSize [protected] |
Referenced by getOverlap(), and Train_Segmenter().
int* Train_Segmenter::compareClusters [protected] |
bool Train_Segmenter::detectOverlap [protected] |
Referenced by train(), and Train_Segmenter().
Vector** Train_Segmenter::distanceVect [protected] |
Referenced by Train_Segmenter().
int Train_Segmenter::fastMerge [protected] |
Referenced by mergeClusters(), and Train_Segmenter().
char Train_Segmenter::label[200] [protected] |
Reimplemented in Adapt_Segmenter.
Referenced by getOverlap(), mergeClusters(), mergeModels(), and train().
int Train_Segmenter::maxDataPoints [protected] |
Referenced by Train_Segmenter().
bool* Train_Segmenter::mergeable [protected] |
Referenced by mergeClusters(), Train_Segmenter(), trainClusters(), and trainModel().
int Train_Segmenter::nrMergeIterations [protected] |
Referenced by mergeClusters(), and Train_Segmenter().
int Train_Segmenter::nrNonMergeModels [protected] |
Referenced by train(), and Train_Segmenter().
int Train_Segmenter::nrScoreClusters [protected] |
int Train_Segmenter::numberOfMerges [protected] |
Referenced by mergeClusters(), and Train_Segmenter().
char Train_Segmenter::outputFileName[2000] [protected] |
Referenced by getOverlap(), mergeClusters(), mergeModels(), and train().
bool Train_Segmenter::prepareForASR [protected] |
Referenced by train(), and Train_Segmenter().
int Train_Segmenter::sadID_decode [protected] |
Referenced by getOverlap(), storeClusters(), train(), and Train_Segmenter().
int Train_Segmenter::sadID_train [protected] |
Referenced by createInitialModels(), getOverlap(), loadClusters(), Adapt_Segmenter::proceedMerge(), train(), Train_Segmenter(), and trainIteration().
TrainPhoneModel** Train_Segmenter::scoreCluster [protected] |
int Train_Segmenter::segID [protected] |
int Train_Segmenter::segID_cheat [protected] |
Referenced by loadClusters(), mergeModels(), train(), and trainIteration().
int Train_Segmenter::segID_decode [protected] |
Referenced by getSegmentation(), loadClusters(), mergeModels(), train(), Train_Segmenter(), and trainIteration().
TrainPhoneModel** Train_Segmenter::trainCluster [protected] |
TrainPhoneModel* Train_Segmenter::trcl [protected] |
Referenced by Train_Segmenter().
PhoneModel* Train_Segmenter::vtlnModel [protected] |