LexicalTree Class Reference
This class contains all lexical tree functionality and also almost all decoder steps. More...
Public Member Functions | |
| LexicalTree (FILE *outFile) | |
| LexicalTree (FILE *outFile, FILE *treeFile, bool useT=true) | |
| ~LexicalTree () | |
| void | processNode (LexicalNode *node, Vector *v) |
| bool | alignmentIsEmpty () |
| int | latticeBaumWelch_numberNodes (LexicalNode *node, int number, bool clear) |
| void | latticeBaumWelch_setLikelihoods (LexicalNode *node, Vector *t, int time, int numberOfStates, double *latticeLikelihood) |
| void | latticeBaumWelch_calculatePosteriors (double *latticeLikelihood, LexicalNode *node, double incomingScore, double *latticeBaumWelchAlfa, double *latticeBaumWelchBeta, double *posteriors, int time, int numberOfStates) |
| void | latticeBaumWelch_mmi_accumulatorsPosteriors (LexicalNode *node, double *posteriors, int numberOfStates, Vector *observation) |
| void | latticeBaumWelch_printPosteriors (LexicalNode *node, double *posteriors, int time, int numberOfStates, int timeOffset) |
| void | latticeBaumWelch_forward (double *latticeLikelihood, LexicalNode *node, double incomingScore, double *latticeBaumWelchAlfa, int time, int numberOfStates) |
| void | latticeBaumWelch_initForward (double *latticeBaumWelchAlfa) |
| double | latticeBaumWelch_backward (double *latticeLikelihood, LexicalNode *node, double *latticeBaumWelchBeta, int time, int numberOfStates, double normFactor, double *resArray) |
| void | latticeBaumWelch_initBackward (double *latticeBaumWelchBeta, int offset) |
| void | setLattice (FILE *latFile) |
| char * | getAlignmentString () |
| void | printInitialSettings (const char *amName, const char *dctName, const char *backName, const char *lmName, bool outXML) |
| void | printFinalSettings (bool outXML, int totMilliSec, int totTime) |
| void | updateGlobalStats () |
| void | checkAMs (int nrM, PhoneModel **models, bool outXML) |
| void | setAMs (PhoneModel **models) |
| void | setLM (LanguageModel *lm) |
| int | getWordID (const char *word) |
| char * | getWord (int wordID) |
| int | getNumberOfWords () |
| bool | setForcedAlign (const char *string) |
| void | setAlignParallel () |
| virtual void | initialiseTree (int startTime=0) |
| void | setInitialLMHistory (const char *word1, const char *word2) |
| void | processVector (Vector **v, int time) |
| void | adaptAMs (Vector *v, int time) |
| void | getLogging (const char *string) |
| void | testArticulatory (ArticulatoryStream *s) |
| int | getBestIDSequence (int *idList, int maxLength, bool showSil, bool notFinishedAllowed) |
| void | getBestRecognition (bool addEndOfSentence, bool outputXML, bool complete, const char *label=NULL, int milliSec=0, int totLength=0, const char *beginTime=NULL, const char *endTime=NULL) |
| double | getBestRecognitionScore () |
| void | storePLConfidence (int time) |
| void | setPhoneLoop (int nrP, PhoneModel **models) |
| void | overwritePrunePars (bool doHist, bool doBeam, bool doEndBeam, double beam, double state_beam, double endstate_beam, bool lmla, int histState, int hist) |
| void | overwriteWeightPars (double lmScale, double transPenalty, double silPenalty) |
| bool | safeBestRecognition (bool addEndOfSentence) |
| LexicalNode * | borrowPhoneString (const char *string) |
| bool | addForcedAlignOOV (LexicalNode *oovNode) |
| void | createWordTree () |
| void | setPhoneLoopConfidence (float *phoneConf, int offset=0) |
| void | printLattice (FILE *latFile, const char *label, int timeEnd) |
| void | printNBestList (FILE *nbestFile=NULL, LatticeNode *node=NULL) |
| void | setTokenDistributionFile (FILE *tdFile) |
| void | setLatticeGeneration (bool setting) |
Protected Member Functions | |
| float | oldcreateLMLAs (LMLAGlobalListType *lmlaGlobal, LexicalNode *node, float *allLMP) |
| void | setNodeContext (LexicalNode *node, int leftContext) |
| void | createLatticeNodeGroups (WLRType *w, double lmScore, int wordID) |
| void | copyLMHistory (int *lmHistory1, int *lmHistory2) |
| bool | compareLMHistory (int *lmHistory1, int *lmHistory2) |
| void | printTokenDistribution () |
| int | createLatticeLMRescoring (LatticeNode *l, NBestList *scoreList, float amTot, float lmTot, int nrWords, int noSilWords, int *lmHist, int sentenceID=0) |
| int | countLatticePaths (LatticeNode *l, int sentenceID=0) |
| void | sortLatticePaths (LatticeNode *l) |
| void | setWlrNBest (WLRType *wlr) |
| int | getWordFromWLR (WLRType *wlr) |
| LatticeNode * | findLatticeNodes (WLRType *wlr) |
| void | printLMParStats (bool outputXML) |
| void | createLattice () |
| void | lattice_copyNonSilArcs (LatticeNode *source, LatticeNode *dest, int loopID) |
| void | lattice_removeDoubleArcs () |
| void | deleteLatticeAdmin () |
| bool | addWordStringToAlignment (LexicalNode *word) |
| int | getLastModelForContext (LexicalNode *node, int wordID) |
| void | calcErrorRegionStats (WLRType *wlr, WLRType *lastCorrect, int firstRef, int lastRef, int *nrWordHyp, float *scoreLM) |
| int | printErrorString (int errorID) |
| void | processVector_LMLAReordering () |
| void | processVector_LMLAReordering_prepare () |
| void | processVector_processNodes (Vector **v) |
| void | createActiveNodesList () |
| void | processVector_prune_processNodesOutput () |
| void | processVector_pruneLM () |
| void | processVector_grammar () |
| void | processVector_administrationCleanup () |
| void | getBestGrammarEndToken (TokenType **bestT, bool notFinishedAllowed) |
| void | setNodeLocationPars (LexicalNode *node, bool fromParallel) |
| void | setDepthLevel (LexicalNode *node, int phone, int depth) |
| void | readTree (LexicalNode *node, FILE *treeFile, int length) |
| void | deleteLookAheadList () |
| void | deleteTree (LexicalNode *node, bool isPar) |
| void | initialiseNode (LexicalNode *node) |
| void | pruneWithMinBeam (LexicalNode *node, float minLikelihood_0) |
| void | deleteNodes () |
| virtual void | processNodeOutput (LexicalNode *node) |
| void | processWord (int wordID, TokenType *token, char isSil, LexicalNode *resultNode) |
| void | getBestPath (WLRType *wlr, bool outputXML, bool complete) |
| void | errorAnalysis (WLRType *wlr, int depth, bool outputXML) |
| void | addNodeToList (LexicalNode *node) |
| void | pruneToken (TokenType **token, float minLikelihood, float binSize=0.0, int *bins=NULL) |
| void | touchWLRpath (WLRType *w) |
| void | touchWLRs (TokenType *token) |
| bool | printWordPronunciation (LexicalNode *node, int wordID) |
| void | checkTreeRobustness (LexicalNode *node) |
| void | initialiseSystem () |
| void | setTreeStartEndMatrix () |
| TokenType * | findBestToken (bool addEndOfSentence, bool complete, bool outputXML, bool notFinishedAllowed=false) |
| LMLAGlobalListType * | getLMLATable (int *lmHistory, bool onlyPrepare) |
| int | getLMLAHashKey (int *lmHistory) |
| void | createLMLAs (LMLAGlobalListType *lmlaGlobal, float *allLMP) |
| void | prepareLMLACreation (LexicalNode *node) |
| void | pruneLMLA () |
| LexicalNode * | getPhoneString (LexicalNode *node, int wordID) |
| void | getPhoneAlignment (const char *prefix, PLRType *pt, int lastFrame, bool confident) |
| LexicalNode * | findCorrectNode (PLRType *pt, int wordID) |
| void | updateStats () |
Protected Attributes | |
| LMLAGlobalListType * | lookAheadUnigram |
| ArticulatoryStream * | myArtStream |
| FastCompressedTree * | fastCompressedTree |
| int | numberOfCompressedNodes |
| int | nodeListLength |
| LexicalNode ** | nodeArray |
| bool | latticeGeneration |
| LexicalNode ** | latticeWordList |
| int | latticeWordListLength |
| int * | tokenDepthAdmin |
| int | biggestNodeDepth |
| int | startTime |
| FILE * | outputFile |
| Output hyp file. | |
| FILE * | tdFile |
| Token Distribution File. | |
| AnalysisSettings * | analysisSettings |
| Used to keep track of analysis administration (blame assignment). | |
| int | blameAssingment [NUMBER_OF_BLAME_CLUSTERS] |
| int | analyse_deletions [NUMBER_OF_BLAME_CLUSTERS] |
| int | analyse_insertions [NUMBER_OF_BLAME_CLUSTERS] |
| int | analyse_substitutions [NUMBER_OF_BLAME_CLUSTERS] |
| int | analyse_totRefWords |
| int | totCategories [3] |
| DecoderSettings | settings |
| WLRType * | bestRecPath |
| Used for adaptation, it would be inconvenient to find the best token each frame. | |
| int | initialLMHist [LM_NGRAM_DEPTH] |
| The history words at the start of a new utterence. | |
| int | nrOfTokens |
| The number of tokens in the tree. | |
| int | timeStamp |
| int | numberOfPhones |
| The number of acoustic models types (not the number in the tree). | |
| int | numberOfWords |
| The number of words in the DCT. | |
| LexicalNode ** | treeEnd |
| The matrix of end-of-word nodes (so called phase-out). | |
| LexicalNode ** | treeStart |
| The matrix of start-of-word nodes (phase-in). | |
| LexicalNode * | grammarStart |
| The start of the tree or (forced-align) grammar. | |
| LexicalNode * | endNode |
| The last node. Only used for forced-align grammars. | |
| int | grammarStartContext |
| Initial left context when starting the system (for forced-align). | |
| WLRType * | wlrStart |
| The first Word-Link-Record (linked together in WLRType). | |
| WLRTypeList * | wlrNBest |
| Each time frame the N-Best wlrs are marked as being one of the best! | |
| LatticeNode * | latticeAdmin |
| A list of all lattice nodes. | |
| int | latticeN |
| int | latticeL |
| char ** | vocabulary |
| The vocabulary. | |
| PhoneModel ** | phoneModels |
| An array of all distinct acoustic models. | |
| int * | wordLength |
| TokenType * | bestToken |
| A pointer to the best token in the tree. | |
| float | bestL |
| The likelihood of token 'bestToken'. | |
| LanguageModel * | languageModel |
| The used language model. | |
| LexicalNodeList * | nodeList |
| A list of all active nodes for the following time frame (so that the tree does not have to be searched). | |
| bool | alignParallel |
| Currently not used! | |
| LMLAGlobalListType * | lmla_list [LMLA_CACHE] |
| The LMLA data structure. (see paper). | |
| float * | transitionPenalty |
| The transition penalty and short-word-penalty can be calculated once in the constructor. | |
| int | intervalTimer |
| float * | phoneLoopConfidence |
| int | phoneLoopConfidenceOffset |
| LexicalNode ** | borrowWordList |
| double * | vList |
| int | threadsRunning |
| MixGaussian ** | pdfUpdateList |
| SearchStatistics | sentenceStats |
| SearchStatistics | globalStats |
| int | startOfSentenceWord |
| The index of the <s> word. | |
| int | endOfSentenceWord |
| The index of the </s> word. | |
| bool | currentlyAligning |
| If TRUE, the system will be aligning. Otherwise it does LVCSR. | |
Detailed Description
This class contains all lexical tree functionality and also almost all decoder steps.The lexical tree (or Pronunciation Prefix Tree (PPT)) is a special form of a pronunciation vocabulary. All words that start with the same phones are put together. As soon as the pronunciation differs, the tree splits into two sub-trees. (for example: "word" and "worst" will share the first two phones.)
This class handles the structure of the tree using LexicalNode, but it also handles tokens being propagated through the tree (including pruning), LM probabilities being added to tokens at tree leaves, LMLA, keeping track of word- and phone-histories, picking the final recognition and storing statistics.
Constructor & Destructor Documentation
| LexicalTree::LexicalTree | ( | FILE * | outFile | ) |
This constructor only initialises some variables.
References analyse_deletions, analyse_insertions, analyse_substitutions, analyse_totRefWords, analysisSettings, bestL, blameAssingment, borrowWordList, currentlyAligning, endNode, endOfSentenceWord, fastCompressedTree, grammarStart, grammarStartContext, initialLMHist, languageModel, latticeAdmin, latticeGeneration, latticeWordList, lmla_list, lookAheadUnigram, nodeArray, nodeList, nodeListLength, numberOfPhones, numberOfWords, outputFile, overwritePrunePars(), overwriteWeightPars(), phoneLoopConfidence, phoneLoopConfidenceOffset, startOfSentenceWord, startTime, tdFile, thread, thread_pdfCalculation(), Thread_pdfCalculation_Data::threadID, threadMayStart, timeStamp, tokenDepthAdmin, totCategories, transitionPenalty, treeEnd, treeStart, vList, vocabulary, wlrNBest, wlrStart, and wordLength.

| LexicalTree::LexicalTree | ( | FILE * | outFile, | |
| FILE * | treeFile, | |||
| bool | useT = true | |||
| ) |
This constructor reads a binary PPT file created with Shout_dct2lextree. It creates the lexical nodes and initialises all variables.
References analyse_deletions, analyse_insertions, analyse_substitutions, analyse_totRefWords, analysisSettings, bestL, blameAssingment, borrowWordList, currentlyAligning, endNode, endOfSentenceWord, fastCompressedTree, WriteFileLittleBigEndian::freadEndianSafe(), grammarStart, grammarStartContext, LexicalNode::inputToken, languageModel, latticeAdmin, latticeGeneration, latticeWordList, lookAheadUnigram, LexicalNode::nextTree, nodeArray, LexicalNode::nodeIsActive, nodeList, nodeListLength, numberOfPhones, numberOfWords, outputFile, overwritePrunePars(), overwriteWeightPars(), phoneLoopConfidence, phoneLoopConfidenceOffset, readTree(), settings, setTreeStartEndMatrix(), startOfSentenceWord, startTime, tdFile, thread, thread_pdfCalculation(), Thread_pdfCalculation_Data::threadID, threadMayStart, timeStamp, LexicalNode::toBeDeletedFromList, tokenDepthAdmin, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, totCategories, transitionPenalty, treeEnd, treeStart, vList, vocabulary, DecoderSettings::weights_TransPenalty, wlrNBest, wlrStart, and wordLength.

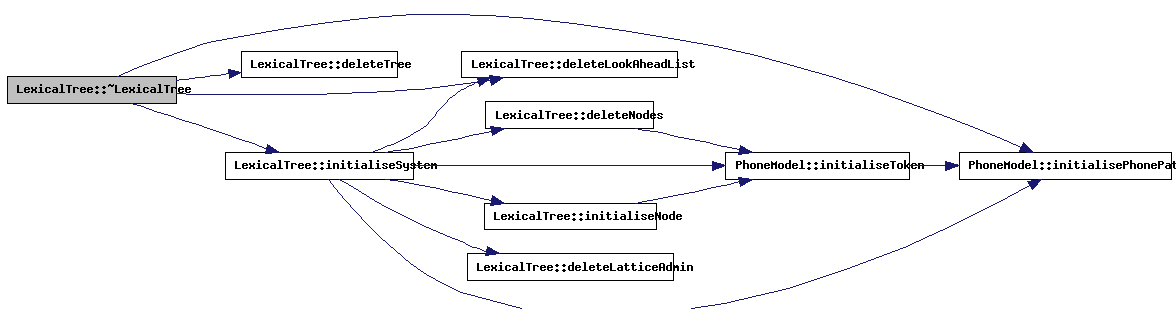
| LexicalTree::~LexicalTree | ( | ) |
The destructor will delete the tree, remaining tokens and LMLA tables.
References analysisSettings, AnalysisSettings::bestScore, AnalysisSettings::bestStateScore, AnalysisSettings::binDistr, borrowWordList, condition_mutexStart, condition_threadStart, AnalysisSettings::correctScore, currentlyAligning, deleteLookAheadList(), deleteTree(), LexicalNode::depth, doPhoneAlignment, endNode, fastCompressedTree, grammarStart, PhoneModel::initialisePhonePath(), initialiseSystem(), LexicalNode::inputToken, latticeWordList, latticeWordListLength, Thread_pdfCalculation_Data::length, LexicalNodeList::next, nodeArray, nodeList, nodeListLength, numberOfPhones, numberOfWords, LexicalNode::parallel, WLRType::phoneAlignment, AnalysisSettings::prunePathAnalyses, AnalysisSettings::prunePathAnalysesLength, AnalysisSettings::stateRanking, thread, threadMayStart, tokCount, tokenDepthAdmin, LexicalNode::tokenSeq, trackCount, transitionPenalty, treeEnd, treeStart, vocabulary, and WLRTracker::w.
Member Function Documentation
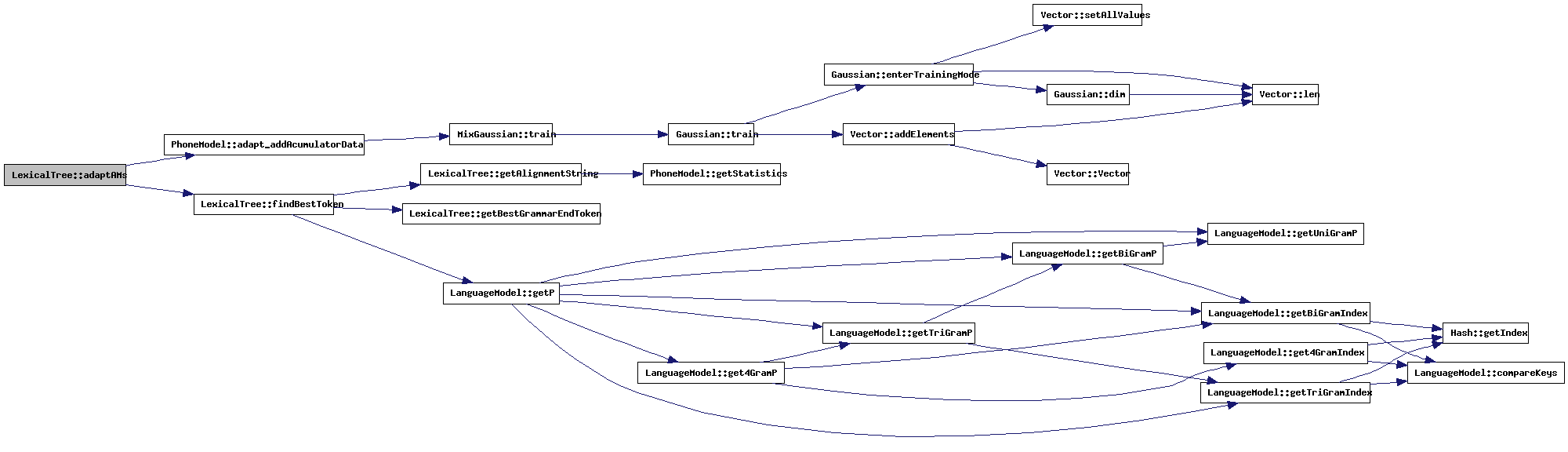
| void LexicalTree::adaptAMs | ( | Vector * | v, | |
| int | time | |||
| ) |
Use the last recognition to adapt the Acoustic Models (fill the numerators)
References PhoneModel::adapt_addAcumulatorData(), bestRecPath, PLRType::contextKey, doPhoneAlignment, findBestToken(), TokenType::path, WLRType::phoneAlignment, PLRType::phoneID, phoneModels, PLRType::previous, WLRType::previous, PLRType::stateOffset, PLRType::timeStamp, and WLRType::timeStamp.
| bool LexicalTree::addForcedAlignOOV | ( | LexicalNode * | oovNode | ) |
When the lexical tree is in alignment mode and it needs to align an OOV word, this method can be used to pass it a word that is borrowed from another lexical tree (background lexicon) using the method borrowPhoneString(). The LM probabilities will be set to 1.
References addWordStringToAlignment(), LexicalNode::contextNext, LexicalNode::contextPrev, currentlyAligning, LexicalNode::depth, endNode, endOfSentenceWord, LexicalNode::inputToken, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, and LexicalNode::wordID.
Referenced by Whisper::Whisper().
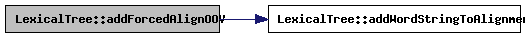
| void LexicalTree::addNodeToList | ( | LexicalNode * | node | ) | [protected] |
This method will add a node to the list of active nodes. This is done when a node has active tokens that need to be processed in later time frames.
References LexicalNodeList::next, LexicalNodeList::node, LexicalNode::nodeIsActive, nodeList, and LexicalNode::toBeDeletedFromList.
Referenced by processNodeOutput(), and processVector_processNodes().
| bool LexicalTree::addWordStringToAlignment | ( | LexicalNode * | word | ) | [protected] |
This helper-method actually adds a phone-string to the back of the alignment-tree. It is called by setForcedAlign() and addForcedAlignOOV().
References alignParallel, LexicalNode::contextKey, LexicalNode::contextNext, LexicalNode::contextPrev, LexicalNode::depth, endNode, endOfSentenceWord, grammarStart, grammarStartContext, LexicalNode::inputToken, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, numberOfPhones, LexicalNode::parallel, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, and LexicalNode::wordID.
Referenced by addForcedAlignOOV(), and setForcedAlign().
| bool LexicalTree::alignmentIsEmpty | ( | ) |
| LexicalNode * LexicalTree::borrowPhoneString | ( | const char * | string | ) |
This method returns a string of nodes with the phones in it belonging to the word that matches the input string. borrowPhoneString() is used for grammars and forced alignment tasks. It is typically used by a background lexical tree and the result is passed to the tree that does not have this word in its system. The word is then named 'OOV'.
References borrowWordList, getPhoneString(), getWordID(), numberOfPhones, numberOfWords, and treeStart.
Referenced by setForcedAlign(), setLattice(), and Whisper::Whisper().

| void LexicalTree::calcErrorRegionStats | ( | WLRType * | wlr, | |
| WLRType * | lastCorrect, | |||
| int | firstRef, | |||
| int | lastRef, | |||
| int * | nrWordHyp, | |||
| float * | scoreLM | |||
| ) | [protected] |
Calculates the LM score of an error region.
References analysisSettings, LanguageModel::getLastWordID(), LanguageModel::getP(), WLRType::isSil, languageModel, WLRTracker::linkWord, WLRType::lmHistory, WLRType::previous, AnalysisSettings::prunePathAnalyses, settings, startOfSentenceWord, WLRType::timeStamp, DecoderSettings::weights_LmScale, and WLRTracker::wordID.
Referenced by errorAnalysis().

| void LexicalTree::checkAMs | ( | int | nrM, | |
| PhoneModel ** | models, | |||
| bool | outXML | |||
| ) |
Checks if the AMs are consistent with the lexical tree structure. This method also sets the models as new LexicalTree acoustic models.
References checkTreeRobustness(), ModelStats::frameMeanLikelihood, PhoneModel::getNumberOfGaussians(), PhoneModel::getStatistics(), ModelStats::likelihood, ModelStats::nrOfContexts, ModelStats::nrOfTrainOcc, numberOfPhones, outputFile, phoneModels, and treeStart.
Referenced by setPhoneLoop(), and Whisper::Whisper().

| void LexicalTree::checkTreeRobustness | ( | LexicalNode * | node | ) | [protected] |
This method is added to check if all phones used in this lexical tree are robust: if a good amount of training occurences were used during creation.
References LexicalNode::modelID, LexicalNode::next, numberOfPhones, and LexicalNode::parallel.
Referenced by checkAMs().
| bool LexicalTree::compareLMHistory | ( | int * | lmHistory1, | |
| int * | lmHistory2 | |||
| ) | [protected] |
Helper method to check if two LM histories are equal (all depths) or unequal (all depths).
Referenced by errorAnalysis(), and getLMLATable().
| void LexicalTree::copyLMHistory | ( | int * | lmHistory1, | |
| int * | lmHistory2 | |||
| ) | [protected] |
Helper method to copy one LM history administration node to another
Referenced by getLMLATable(), initialiseTree(), printLMParStats(), processNodeOutput(), processWord(), and safeBestRecognition().
| int LexicalTree::countLatticePaths | ( | LatticeNode * | l, | |
| int | sentenceID = 0 | |||
| ) | [protected] |
Determines how many paths there are through the lattice.
References WLRType::lattice, WLRList::next, LatticeNode::outArcs, and WLRList::wlr.
Referenced by printLMParStats().
| void LexicalTree::createActiveNodesList | ( | void | ) | [protected] |
- Todo:
- docs
References LexicalNodeList::next, LexicalNodeList::node, nodeArray, LexicalNode::nodeIsActive, nodeList, and nodeListLength.
Referenced by createLattice(), and processVector_processNodes().
| void LexicalTree::createLattice | ( | ) | [protected] |
This method will create the lattice structure, given a set with WLR objects (after decoding).
References LatticeNode::adminNext, WLRList::amScore, createActiveNodesList(), createLatticeNodeGroups(), deleteLatticeAdmin(), LatticeNode::exampleWord, findBestToken(), LatticeNode::inArcs, PhoneModel::initialiseToken(), lattice_removeDoubleArcs(), latticeAdmin, latticeL, latticeN, WLRList::lmScore, WLRType::nBest, WLRList::next, TokenType::next, LatticeNode::nodeNr, LatticeNode::outArcs, TokenType::path, processVector_administrationCleanup(), startOfSentenceWord, startTime, LatticeNode::timeBegin, LatticeNode::timeEnd, WLRType::timeStamp, timeStamp, WLRList::totScore, touchWLRs(), WLRList::wlr, and LatticeNode::wordID.
Referenced by printLattice(), printLMParStats(), and printNBestList().
| int LexicalTree::createLatticeLMRescoring | ( | LatticeNode * | l, | |
| NBestList * | scoreList, | |||
| float | amTot, | |||
| float | lmTot, | |||
| int | nrWords, | |||
| int | noSilWords, | |||
| int * | lmHist, | |||
| int | sentenceID = 0 | |||
| ) | [protected] |
We need an array with all possible paths through the lattice. Once we have this array (filled with AM and LM scores) we can rescore very quickly!
References WLRList::amScore, LanguageModel::getP(), languageModel, WLRType::lattice, WLRList::next, NBestList::noSilWords, NBestList::nrWords, LatticeNode::outArcs, startOfSentenceWord, NBestList::totAM, NBestList::totLM, WLRList::wlr, and LatticeNode::wordID.
Referenced by printLMParStats().

| void LexicalTree::createLatticeNodeGroups | ( | WLRType * | w, | |
| double | lmScore, | |||
| int | wordID | |||
| ) | [protected] |
References WLRList::amScore, WLRType::COMBlikelihood, findLatticeNodes(), LanguageModel::getLastWordID(), LanguageModel::getP(), LatticeNode::inArcs, languageModel, WLRType::lattice, latticeAdmin, WLRType::lmHistory, WLRType::LMlikelihood, WLRList::lmScore, WLRType::nBest, WLRList::next, WLRType::previous, settings, startOfSentenceWord, WLRList::totScore, DecoderSettings::weights_LmScale, and WLRList::wlr.
Referenced by createLattice().

| void LexicalTree::createLMLAs | ( | LMLAGlobalListType * | lmlaGlobal, | |
| float * | allLMP | |||
| ) | [protected] |
This method creates a new LMLA table and adds it to the global LMLA list.
References Thread_LMLACalculation_Data::allLMP, fastCompressedTree, lmla_condition_mutexDone, lmla_condition_mutexStart, lmla_condition_threadDone, lmla_condition_threadStart, lmla_threadFinished, lmla_threadMayStart, lmlaCount, Thread_LMLACalculation_Data::lmlaGlobal, LMLAGlobalListType::lookAhead, FastCompressedTree::nextIndex, numberOfCompressedNodes, and FastCompressedTree::wordID.
Referenced by getLMLATable().
| void LexicalTree::createWordTree | ( | ) |
| void LexicalTree::deleteLatticeAdmin | ( | ) | [protected] |
Cleans up the lattice administration.
References LatticeNode::adminNext, LatticeNode::inArcs, latticeAdmin, WLRList::next, and LatticeNode::outArcs.
Referenced by createLattice(), and initialiseSystem().
| void LexicalTree::deleteLookAheadList | ( | ) | [protected] |
This method deletes all LM lookahead data (the global lookahead list).
References lmla_list, LMLAGlobalListType::lookAhead, lookAheadUnigram, and LMLAGlobalListType::next.
Referenced by initialiseSystem(), and ~LexicalTree().
| void LexicalTree::deleteNodes | ( | ) | [protected] |
All nodes in the lexical node list 'node' are initialised (active tokens are deleted) and after that the entries in the lexical node list are all deleted (not the nodes itself!)
- Todo:
- The names of the variables are unclear. Change them!
References PhoneModel::initialiseToken(), LexicalNode::inputToken, nodeArray, nodeListLength, LexicalNode::tokenSeq, and LexicalNode::tokenSeqLength.
Referenced by initialiseSystem().

| void LexicalTree::deleteTree | ( | LexicalNode * | node, | |
| bool | isPar | |||
| ) | [protected] |
This method deletes the lexical tree (PPT) and all its nodes.
References LexicalNode::depth, gaussianCount, LexicalNode::inputToken, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, tokCount, and LexicalNode::tokenSeq.
Referenced by Segmenter::createLexicalTree(), setForcedAlign(), setLattice(), and ~LexicalTree().
| void LexicalTree::errorAnalysis | ( | WLRType * | wlr, | |
| int | depth, | |||
| bool | outputXML | |||
| ) | [protected] |
This method determines the error regions and performs blame assignment. The depth should be set to zero. The method uses this variable for recursive calls.
References AM, AMLM, analyse_deletions, analyse_insertions, analyse_substitutions, analyse_totRefWords, analysisSettings, blameAssingment, calcErrorRegionStats(), WLRType::COMBlikelihood, compareLMHistory(), AnalysisSettings::containsOOV, doPhoneAlignment, WLRTracker::errorCategory, AnalysisSettings::errorRegionActive, WLRTracker::errorRegionID, getPhoneAlignment(), getWordFromWLR(), WLRTracker::linkWord, LM, WLRType::lmHistory, WLRType::LMlikelihood, NBestList::noSilWords, OOV, outputFile, WLRType::phoneAlignment, PLRType::phoneID, PLRType::previous, WLRType::previous, printErrorString(), AnalysisSettings::prunePathAnalyses, AnalysisSettings::prunePathAnalysesLength, AnalysisSettings::refStats, SEARCH, settings, startOfSentenceWord, PLRType::timeStamp, WLRType::timeStamp, UNKNOWN, vocabulary, WLRTracker::w, DecoderSettings::weights_LmScale, and WLRTracker::wordID.
Referenced by getBestRecognition().

| TokenType * LexicalTree::findBestToken | ( | bool | addEndOfSentence, | |
| bool | complete, | |||
| bool | outputXML, | |||
| bool | notFinishedAllowed = false | |||
| ) | [protected] |
This method will look in the lexical tree for the best token. If no token is found, it will return NULL. If a pointer to a string is provided, logging will be stored in this string.
References currentlyAligning, endNode, endOfSentenceWord, getAlignmentString(), getBestGrammarEndToken(), LanguageModel::getP(), grammarStart, LexicalNode::inputToken, languageModel, latticeWordList, TokenType::likelihood, WLRType::lmHistory, TokenType::next, numberOfPhones, outputFile, TokenType::path, settings, treeStart, and DecoderSettings::weights_LmScale.
Referenced by adaptAMs(), createLattice(), Segmenter::createSegments(), getBestIDSequence(), getBestRecognition(), getBestRecognitionScore(), and safeBestRecognition().
| LexicalNode * LexicalTree::findCorrectNode | ( | PLRType * | pt, | |
| int | wordID | |||
| ) | [protected] |
Returns the node in the lexical tree that correstponds to the PLRType string *pt. wordID should only be > 0 if the phone pt is the last phone of the word.
References LexicalNode::contextKey, PLRType::contextKey, LexicalNode::next, numberOfPhones, LexicalNode::parallel, PLRType::phoneID, PLRType::previous, treeEnd, and treeStart.
| LatticeNode * LexicalTree::findLatticeNodes | ( | WLRType * | wlr | ) | [protected] |
This lattice will search for existing lattice-nodes that are needed for wlr. If either of them does not exists, it will be created.
References LatticeNode::adminNext, LatticeNode::exampleWord, getWordFromWLR(), LatticeNode::inArcs, latticeAdmin, LatticeNode::outArcs, WLRType::previous, LatticeNode::timeBegin, LatticeNode::timeEnd, WLRType::timeStamp, and LatticeNode::wordID.
Referenced by createLatticeNodeGroups().

| char * LexicalTree::getAlignmentString | ( | ) |
Returns a string of all phones in the alignment task.
References PhoneModel::getStatistics(), grammarStart, LexicalNode::modelID, ModelStats::name, LexicalNode::next, LexicalNode::nextTree, and phoneModels.
Referenced by findBestToken().

| void LexicalTree::getBestGrammarEndToken | ( | TokenType ** | bestT, | |
| bool | notFinishedAllowed | |||
| ) | [protected] |
The best grammar end-token is returned.
References endNode, LexicalNode::inputToken, TokenType::likelihood, and TokenType::next.
Referenced by findBestToken().
| int LexicalTree::getBestIDSequence | ( | int * | idList, | |
| int | maxLength, | |||
| bool | showSil, | |||
| bool | notFinishedAllowed | |||
| ) |
- Todo:
- Docs
References findBestToken(), LanguageModel::getLastWordID(), WLRType::isSil, languageModel, WLRType::lmHistory, TokenType::path, WLRType::previous, startOfSentenceWord, startTime, and WLRType::timeStamp.
Referenced by ShoutOnline::ShoutOnline().

| void LexicalTree::getBestPath | ( | WLRType * | wlr, | |
| bool | outputXML, | |||
| bool | complete | |||
| ) | [protected] |
This method recursively goes through the Word Link Records of a (normaly the best) recognition and prints to recognized words to the string 'string'.
If 'complete' is true, also alignment and likelihood data is print.
If phone alignment is switched on (configuration switch) also the phone alignment data is printed to the string.
References WLRType::COMBlikelihood, doPhoneAlignment, LanguageModel::getLastWordID(), getPhoneAlignment(), WLRType::isSil, languageModel, WLRType::lmHistory, WLRType::LMlikelihood, outputFile, WLRType::phoneAlignment, phoneLoopConfidence, phoneLoopConfidenceOffset, WLRType::previous, startOfSentenceWord, startTime, WLRType::timeStamp, and vocabulary.
Referenced by getBestRecognition().
| void LexicalTree::getBestRecognition | ( | bool | addEndOfSentence, | |
| bool | outputXML, | |||
| bool | complete, | |||
| const char * | label = NULL, |
|||
| int | milliSec = 0, |
|||
| int | totLength = 0, |
|||
| const char * | beginTime = NULL, |
|||
| const char * | endTime = NULL | |||
| ) |
This method will find the best found recognition and print it to standard output. If 'complete' is true, the string will also contain timing and likelihood data.
References analysisSettings, bestRecPath, errorAnalysis(), findBestToken(), getBestPath(), TokenType::likelihood, TokenType::lookAheadV, AnalysisSettings::maxBeam, AnalysisSettings::maxEndStateBeam, AnalysisSettings::maxHistogram, AnalysisSettings::maxStateBeam, AnalysisSettings::maxStateHistogram, myArtStream, NBestList::noSilWords, SearchStatistics::nrOfActiveNodes, SearchStatistics::nrOfActiveNodes_Max, SearchStatistics::nrOfActiveTokens, SearchStatistics::nrOfActiveTokens_Max, SearchStatistics::nrOfCleanUps, SearchStatistics::nrOfHistPruning, SearchStatistics::nrOfLMLATables, SearchStatistics::nrOfLMLATables_Max, nrOfStateHistPruning, outputFile, TokenType::path, DecoderSettings::prune_Hist, AnalysisSettings::refStats, sentenceStats, settings, and ArticulatoryStream::testPrint().
Referenced by Whisper::Whisper().
| double LexicalTree::getBestRecognitionScore | ( | ) |
This method will return the total score of the best recognition (used for VTLN)
References WLRType::COMBlikelihood, findBestToken(), and TokenType::path.

| int LexicalTree::getLastModelForContext | ( | LexicalNode * | node, | |
| int | wordID | |||
| ) | [protected] |
This method searches for a word with word ID 'wordID' and returns the last phone model ID. This method is used to find the correct left-context for the first phone in forced alignment.
References LexicalNode::modelID, LexicalNode::next, LexicalNode::parallel, and LexicalNode::wordID.
Referenced by setInitialLMHistory().
| int LexicalTree::getLMLAHashKey | ( | int * | lmHistory | ) | [protected] |
This method calculates a hash key for an LMLA table.
A simple modulo function is used: modulo-LMLA_CACHE(sum(lmHistory[i]))
Referenced by getLMLATable().
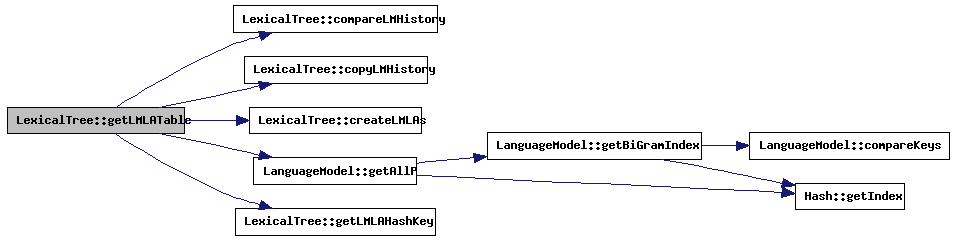
| LMLAGlobalListType * LexicalTree::getLMLATable | ( | int * | lmHistory, | |
| bool | onlyPrepare | |||
| ) | [protected] |
Given the LM history 'lmHistory' a pointer to the corresponding LMLA table is returned. If the table does not exist, it is created.
References LMLAGlobalListType::collissionTime, compareLMHistory(), copyLMHistory(), createLMLAs(), LanguageModel::getAllP(), getLMLAHashKey(), languageModel, lmla_list, lmlaCount, LMLAGlobalListType::lookAhead, lookAheadUnigram, LMLAGlobalListType::next, SearchStatistics::nrOfLMLATables_Temp, numberOfCompressedNodes, numberOfWords, sentenceStats, settings, transitionPenalty, DecoderSettings::weights_LmScale, and LMLAGlobalListType::wordHistory.
Referenced by processVector_LMLAReordering(), and processVector_LMLAReordering_prepare().
| void LexicalTree::getLogging | ( | const char * | string | ) |
| int LexicalTree::getNumberOfWords | ( | ) |
Returns the number of words in the current vocabulary (PPT)
References numberOfWords.
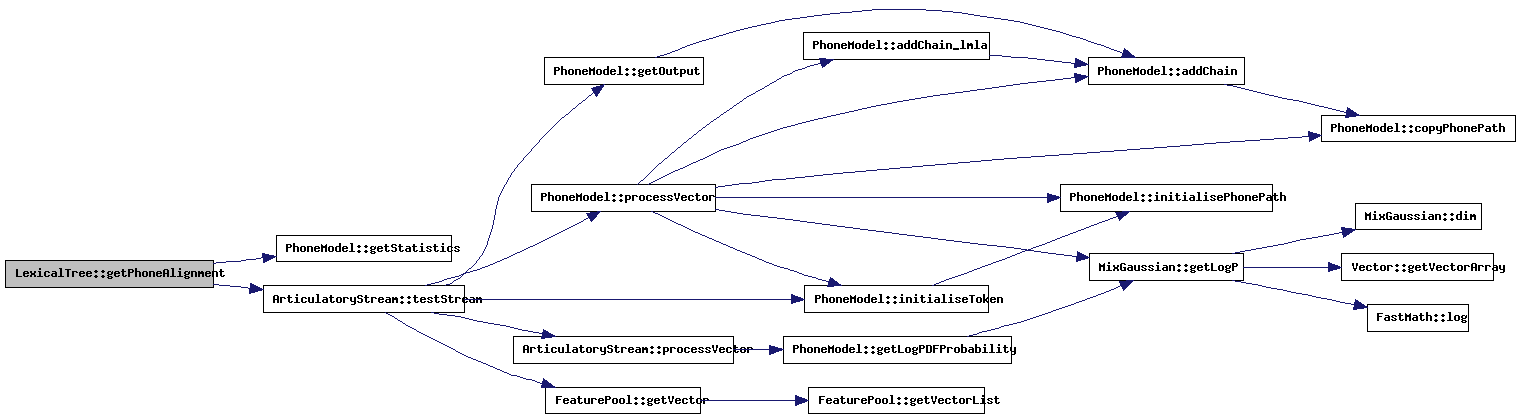
| void LexicalTree::getPhoneAlignment | ( | const char * | prefix, | |
| PLRType * | pt, | |||
| int | lastFrame, | |||
| bool | confident | |||
| ) | [protected] |
Returns the phone alignment. Called by getBestPath() when the configuration switch "phone-based" is defined.
References PLRType::contextKey, PhoneModel::getStatistics(), ModelStats::isSil, PLRType::likelihood, myArtStream, ModelStats::name, numberOfPhones, outputFile, PLRType::phoneID, phoneLoopConfidence, phoneLoopConfidenceOffset, phoneModels, PLRType::previous, settings, PLRType::stateOffset, ArticulatoryStream::testStream(), and PLRType::timeStamp.
Referenced by errorAnalysis(), and getBestPath().
| LexicalNode * LexicalTree::getPhoneString | ( | LexicalNode * | node, | |
| int | wordID | |||
| ) | [protected] |
This method returns a string of nodes with the phones in it belonging to the word with ID 'wordID'. getPhoneString() is used for grammars and forced alignment tasks. It will give the most left and most right phones a context of -1.
References LexicalNode::compressedTreeIndex, LexicalNode::contextKey, LexicalNode::contextNext, LexicalNode::contextPrev, LexicalNode::depth, LexicalNode::inputToken, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::nodeIsActive, LexicalNode::parallel, LexicalNode::toBeDeletedFromList, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, and LexicalNode::wordID.
Referenced by borrowPhoneString().
| char * LexicalTree::getWord | ( | int | wordID | ) |
Given a wordID, the corresponding word string is returned. If the wordID is not valid, NULL is returned.
References vocabulary.
Referenced by printWordPronunciation(), and ShoutOnline::ShoutOnline().
| int LexicalTree::getWordFromWLR | ( | WLRType * | wlr | ) | [protected] |
Calculates the last wordID given a WLRType object.
References LanguageModel::getLastWordID(), WLRType::isSil, languageModel, WLRType::lmHistory, and startOfSentenceWord.
Referenced by errorAnalysis(), findLatticeNodes(), and setWlrNBest().

| int LexicalTree::getWordID | ( | const char * | word | ) |
Returns the ID of the word 'word'. If the word is not in the vocabulary (OOV), -1 is returned.
References numberOfWords, and vocabulary.
Referenced by borrowPhoneString(), setInitialLMHistory(), and ShoutOnline::ShoutOnline().
| void LexicalTree::initialiseNode | ( | LexicalNode * | node | ) | [protected] |
This method will initialise a node and its parallel nodes, following nodes and nodes of following trees (if any). Initialising a node means deleting all input and internal token lists.
References LexicalNode::compressedTreeIndex, LexicalNode::depth, PhoneModel::initialiseToken(), LexicalNode::inputToken, latticeWordList, LexicalNode::next, LexicalNode::nextTree, LexicalNode::nodeIsActive, LexicalNode::parallel, LexicalNode::toBeDeletedFromList, LexicalNode::tokenSeq, and LexicalNode::tokenSeqLength.
Referenced by initialiseSystem().

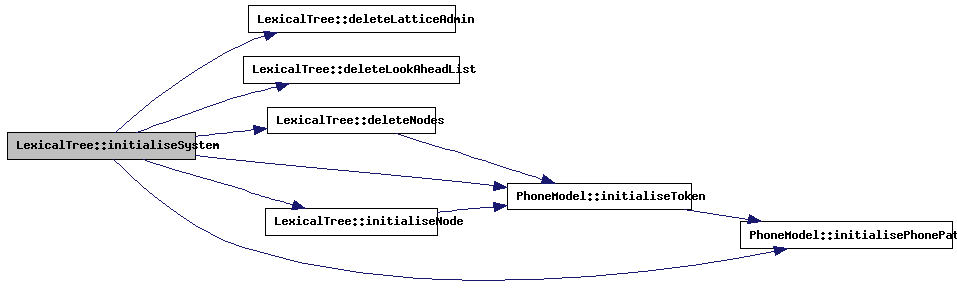
| void LexicalTree::initialiseSystem | ( | ) | [protected] |
All pending data will be cleaned up and all parameters are reset to their initial values, so that a new recognition run can start over cleanly.
References WLRType::adminNext, bestL, bestRecPath, deleteLatticeAdmin(), deleteLookAheadList(), deleteNodes(), doPhoneAlignment, endNode, grammarStart, initialiseNode(), PhoneModel::initialisePhonePath(), PhoneModel::initialiseToken(), LexicalNode::inputToken, intervalTimer, WLRTypeList::next, LexicalNodeList::next, nodeArray, LexicalNode::nodeIsActive, nodeList, nodeListLength, SearchStatistics::nrOfActiveNodes, SearchStatistics::nrOfActiveNodes_Max, SearchStatistics::nrOfActiveNodes_Prev, SearchStatistics::nrOfActiveTokens, SearchStatistics::nrOfActiveTokens_Max, SearchStatistics::nrOfActiveTokens_Prev, SearchStatistics::nrOfCleanUps, SearchStatistics::nrOfHistPruning, SearchStatistics::nrOfLMLATables, SearchStatistics::nrOfLMLATables_Max, SearchStatistics::nrOfLMLATables_Prev, SearchStatistics::nrOfLMLATables_Temp, nrOfStateHistPruning, nrOfTokens, numberOfPhones, LexicalNode::parallel, WLRType::phoneAlignment, sentenceStats, settings, timeStamp, LexicalNode::toBeDeletedFromList, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, treeEnd, treeStart, DecoderSettings::weights_LmScale, wlrCount, wlrNBest, and wlrStart.
Referenced by Segmenter::createLexicalTree(), initialiseTree(), setForcedAlign(), setLattice(), Train_Segmenter::train(), and ~LexicalTree().
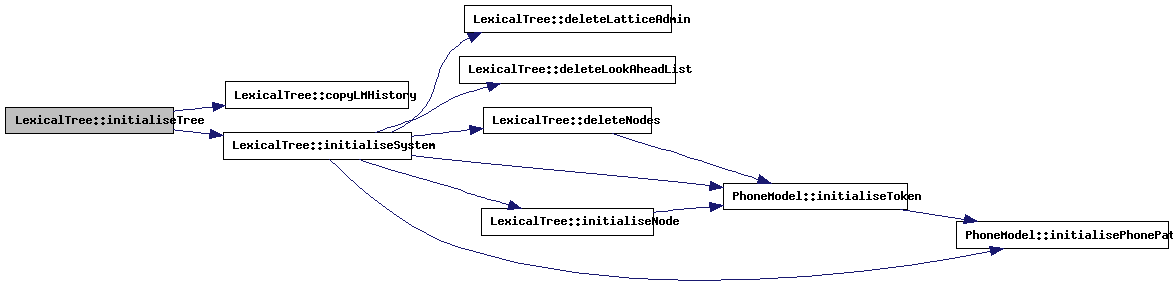
| void LexicalTree::initialiseTree | ( | int | sTime = 0 |
) | [virtual] |
This method initialises the entire tree. The application needs to call this method before recognition can start. All LMLA tables and token lists are deleted and a single new token is created that is fed to the root of the tree. Also, statistics are reset.
References WLRType::adminNext, WLRType::COMBlikelihood, copyLMHistory(), doPhoneAlignment, grammarStart, grammarStartContext, initialiseSystem(), initialLMHist, LexicalNode::inputToken, WLRType::isSil, WLRType::lattice, latticeWordList, WLRType::lmHistory, WLRType::LMlikelihood, WLRType::nBest, LexicalNode::nextTree, nodeArray, LexicalNode::nodeIsActive, nodeListLength, numberOfPhones, LexicalNode::parallel, WLRType::phoneAlignment, plrCount, WLRType::previous, startTime, timeStamp, WLRType::timeStamp, LexicalNode::toBeDeletedFromList, tokCount, treeStart, WLRType::usedAt, wlrCount, and wlrStart.
Referenced by Segmenter::segmentFeaturePool(), ShoutOnline::ShoutOnline(), and Whisper::Whisper().
| void LexicalTree::lattice_copyNonSilArcs | ( | LatticeNode * | source, | |
| LatticeNode * | dest, | |||
| int | loopID | |||
| ) | [protected] |
| void LexicalTree::lattice_removeDoubleArcs | ( | ) | [protected] |
References LatticeNode::adminNext, WLRList::amScore, LatticeNode::inArcs, WLRType::lattice, latticeAdmin, WLRList::lmScore, WLRList::next, WLRList::totScore, and WLRList::wlr.
Referenced by createLattice().
| double LexicalTree::latticeBaumWelch_backward | ( | double * | latticeLikelihood, | |
| LexicalNode * | node, | |||
| double * | beta, | |||
| int | time, | |||
| int | numberOfStates, | |||
| double | normFactor, | |||
| double * | resArray | |||
| ) |
- Todo:
- Docs
References LexicalNode::compressedTreeIndex, LexicalNode::contextKey, endNode, PhoneModel::getStatistics(), PhoneModel::getTransition(), grammarStart, ModelStats::isSil, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, and phoneModels.
Referenced by Whisper::Whisper().

| void LexicalTree::latticeBaumWelch_calculatePosteriors | ( | double * | latticeLikelihood, | |
| LexicalNode * | node, | |||
| double | incomingScore, | |||
| double * | alfa, | |||
| double * | beta, | |||
| double * | posteriors, | |||
| int | time, | |||
| int | numberOfStates | |||
| ) |
- Todo:
- Docs
References LexicalNode::compressedTreeIndex, LexicalNode::contextKey, PhoneModel::getStatistics(), PhoneModel::getTransition(), grammarStart, ModelStats::isSil, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, and phoneModels.
Referenced by Whisper::Whisper().

| void LexicalTree::latticeBaumWelch_forward | ( | double * | latticeLikelihood, | |
| LexicalNode * | node, | |||
| double | incomingScore, | |||
| double * | alfa, | |||
| int | time, | |||
| int | numberOfStates | |||
| ) |
- Todo:
- Docs
References LexicalNode::compressedTreeIndex, LexicalNode::contextKey, PhoneModel::getStatistics(), PhoneModel::getTransition(), grammarStart, ModelStats::isSil, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, and phoneModels.
Referenced by Whisper::Whisper().

| void LexicalTree::latticeBaumWelch_initBackward | ( | double * | beta, | |
| int | offset | |||
| ) |
- Todo:
- Docs
References LexicalNode::compressedTreeIndex, endNode, and LexicalNode::parallel.
Referenced by Whisper::Whisper().
| void LexicalTree::latticeBaumWelch_initForward | ( | double * | latticeBaumWelchAlfa | ) |
- Todo:
- Docs
References LexicalNode::compressedTreeIndex, grammarStart, and LexicalNode::parallel.
Referenced by Whisper::Whisper().
| void LexicalTree::latticeBaumWelch_mmi_accumulatorsPosteriors | ( | LexicalNode * | node, | |
| double * | posteriors, | |||
| int | numberOfStates, | |||
| Vector * | observation | |||
| ) |
- Todo:
- Docs
References PhoneModel::adapt_addAcumulatorData(), LexicalNode::compressedTreeIndex, LexicalNode::contextKey, grammarStart, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, and phoneModels.
Referenced by Whisper::Whisper().

| int LexicalTree::latticeBaumWelch_numberNodes | ( | LexicalNode * | node, | |
| int | number, | |||
| bool | clear | |||
| ) |
- Todo:
- Docs
References LexicalNode::compressedTreeIndex, grammarStart, LexicalNode::next, LexicalNode::nextTree, and LexicalNode::parallel.
Referenced by Whisper::Whisper().
| void LexicalTree::latticeBaumWelch_printPosteriors | ( | LexicalNode * | node, | |
| double * | posteriors, | |||
| int | time, | |||
| int | numberOfStates, | |||
| int | timeOffset | |||
| ) |
| void LexicalTree::latticeBaumWelch_setLikelihoods | ( | LexicalNode * | node, | |
| Vector * | t, | |||
| int | time, | |||
| int | numberOfStates, | |||
| double * | latticeLikelihood | |||
| ) |
- Todo:
- Docs
References LexicalNode::compressedTreeIndex, LexicalNode::contextKey, PhoneModel::getPDFProbability(), PhoneModel::getStatistics(), grammarStart, ModelStats::isSil, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, and phoneModels.
Referenced by Whisper::Whisper().

| float LexicalTree::oldcreateLMLAs | ( | LMLAGlobalListType * | lmlaGlobal, | |
| LexicalNode * | node, | |||
| float * | allLMP | |||
| ) | [protected] |
| void LexicalTree::overwritePrunePars | ( | bool | doHist, | |
| bool | doBeam, | |||
| bool | doEndState, | |||
| double | beam, | |||
| double | state_beam, | |||
| double | endstate_beam, | |||
| bool | lmla, | |||
| int | histState, | |||
| int | hist | |||
| ) |
Sets the pruning decoder settings for this tree.
References DecoderSettings::doBeam, DecoderSettings::doEndState, DecoderSettings::doHist, DecoderSettings::prune_Beam, DecoderSettings::prune_EndStateBeam, DecoderSettings::prune_Hist, DecoderSettings::prune_HistState, DecoderSettings::prune_Lmla, DecoderSettings::prune_StateBeam, and settings.
Referenced by LexicalTree(), Segmenter::Segmenter(), ShoutOnline::ShoutOnline(), and Whisper::Whisper().
| void LexicalTree::overwriteWeightPars | ( | double | lmScale, | |
| double | transPenalty, | |||
| double | silPenalty | |||
| ) |
Sets the weight decoder settings for this tree.
References settings, DecoderSettings::weights_LmScale, DecoderSettings::weights_SilPenalty, and DecoderSettings::weights_TransPenalty.
Referenced by LexicalTree(), Segmenter::Segmenter(), ShoutOnline::ShoutOnline(), Train_Segmenter::Train_Segmenter(), and Whisper::Whisper().
| void LexicalTree::prepareLMLACreation | ( | LexicalNode * | node | ) | [protected] |
| int LexicalTree::printErrorString | ( | int | errorID | ) | [protected] |
| void LexicalTree::printFinalSettings | ( | bool | outXML, | |
| int | totMilliSec, | |||
| int | totTime | |||
| ) |
This method prints some final statistics such as average RealTime factor.
References AM, AMLM, analyse_deletions, analyse_insertions, analyse_substitutions, analyse_totRefWords, analysisSettings, blameAssingment, globalStats, LM, SearchStatistics::nrOfActiveNodes, SearchStatistics::nrOfActiveNodes_Max, SearchStatistics::nrOfActiveTokens, SearchStatistics::nrOfActiveTokens_Max, SearchStatistics::nrOfCleanUps, SearchStatistics::nrOfLMLATables, SearchStatistics::nrOfLMLATables_Max, OOV, outputFile, SEARCH, and UNKNOWN.
Referenced by Whisper::Whisper().
| void LexicalTree::printInitialSettings | ( | const char * | amName, | |
| const char * | dctName, | |||
| const char * | backName, | |||
| const char * | lmName, | |||
| bool | outXML | |||
| ) |
This method prints a welcoming message and initial statistics (such as tree depth etc)
References globalStats, SearchStatistics::nrOfActiveNodes, SearchStatistics::nrOfActiveNodes_Max, SearchStatistics::nrOfActiveNodes_Prev, SearchStatistics::nrOfActiveTokens, SearchStatistics::nrOfActiveTokens_Max, SearchStatistics::nrOfActiveTokens_Prev, SearchStatistics::nrOfCleanUps, SearchStatistics::nrOfLMLATables, SearchStatistics::nrOfLMLATables_Max, SearchStatistics::nrOfLMLATables_Prev, SearchStatistics::nrOfLMLATables_Temp, outputFile, DecoderSettings::prune_Beam, DecoderSettings::prune_EndStateBeam, DecoderSettings::prune_Hist, DecoderSettings::prune_HistState, DecoderSettings::prune_Lmla, DecoderSettings::prune_StateBeam, settings, DecoderSettings::weights_LmScale, DecoderSettings::weights_SilPenalty, and DecoderSettings::weights_TransPenalty.
Referenced by ShoutOnline::ShoutOnline(), and Whisper::Whisper().
| void LexicalTree::printLattice | ( | FILE * | latFile, | |
| const char * | label, | |||
| int | timeEnd | |||
| ) |
This method will print the lattice output.
References LatticeNode::adminNext, WLRList::amScore, createLattice(), LatticeNode::inArcs, WLRType::lattice, latticeAdmin, latticeL, latticeN, WLRList::next, LatticeNode::nodeNr, startOfSentenceWord, LatticeNode::timeEnd, WLRType::timeStamp, vocabulary, WLRList::wlr, and LatticeNode::wordID.
Referenced by Whisper::Whisper().
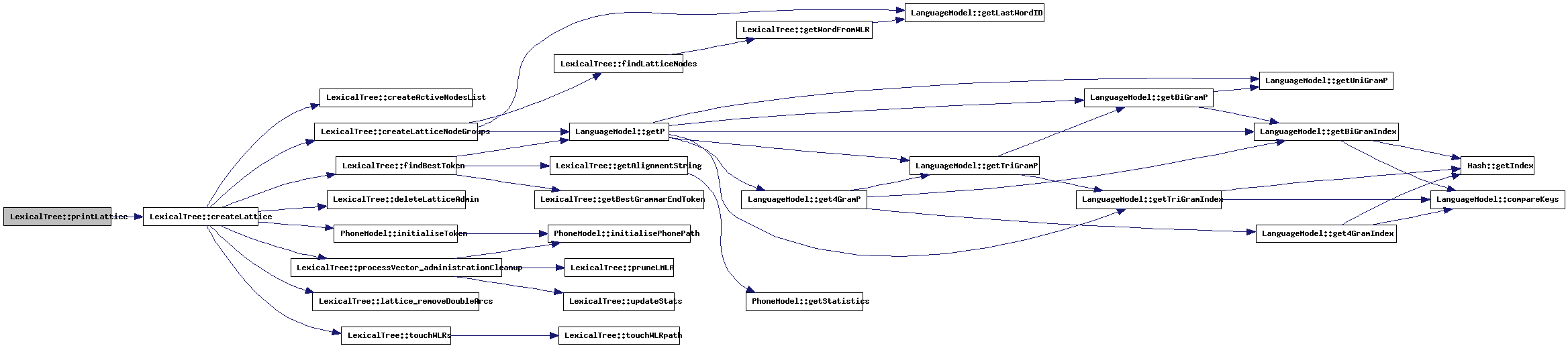
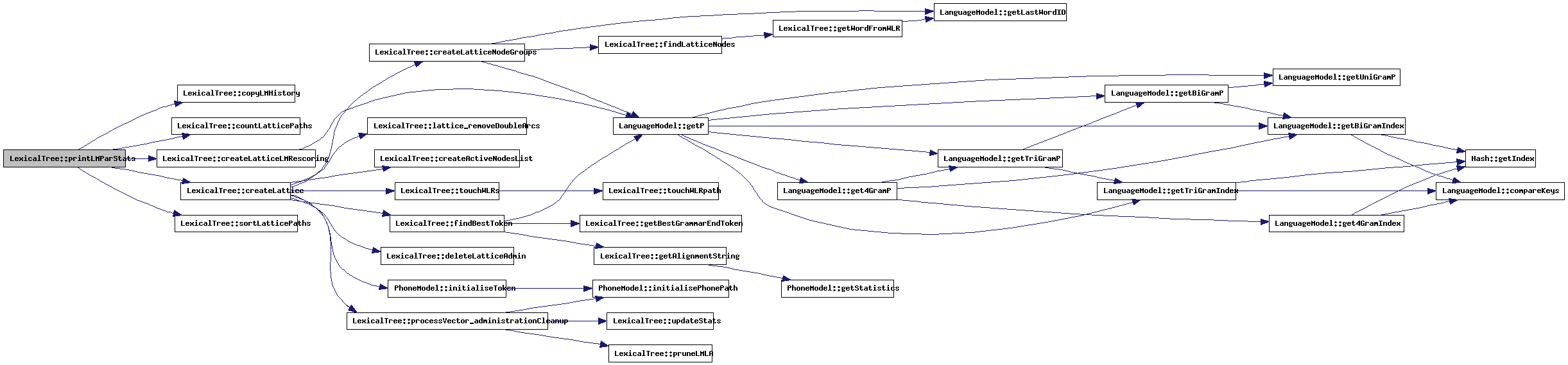
| void LexicalTree::printLMParStats | ( | bool | outputXML | ) | [protected] |
This method will create a lattice, rescore the LM-parameters in various ways and print the resulting statistics.
References analysisSettings, AnalysisSettings::containsOOV, copyLMHistory(), countLatticePaths(), createLattice(), createLatticeLMRescoring(), initialLMHist, latticeAdmin, NBestList::noSilWords, outputFile, AnalysisSettings::refStats, sortLatticePaths(), NBestList::totAM, and NBestList::totLM.
| void LexicalTree::printNBestList | ( | FILE * | nbestFile = NULL, |
|
| LatticeNode * | l = NULL | |||
| ) |
This method will print the N-Best list output.
References createLattice(), WLRType::lattice, latticeAdmin, WLRList::next, LatticeNode::outArcs, outputFile, vocabulary, WLRList::wlr, and LatticeNode::wordID.
Referenced by Whisper::Whisper().

| void LexicalTree::printTokenDistribution | ( | ) | [protected] |
Prints the token distribution for this time frame..
References biggestNodeDepth, tdFile, and tokenDepthAdmin.
Referenced by processVector().
| bool LexicalTree::printWordPronunciation | ( | LexicalNode * | node, | |
| int | wordID | |||
| ) | [protected] |
Print all words followed with their pronunciation that are reachable from node 'node'. If the root node is used, all words from the PPT are printed.
References PhoneModel::getStatistics(), getWord(), LexicalNode::modelID, ModelStats::name, LexicalNode::next, outputFile, LexicalNode::parallel, phoneModels, and LexicalNode::wordID.

| void LexicalTree::processNode | ( | LexicalNode * | node, | |
| Vector * | v | |||
| ) |
All nodes that are in the global active node list will be passed to this method every time frame. The tokens in these nodes will be updated using the acoustic models (and observation v) language model and lookahead values. See paper [XXXX] for more information.
References bestL, LexicalNode::compressedTreeIndex, LexicalNode::contextKey, currentlyAligning, LexicalNode::depth, DecoderSettings::doBeam, LexicalNode::inputToken, LexicalNode::modelID, phoneModels, PhoneModel::processVector(), DecoderSettings::prune_Lmla, settings, tdFile, timeStamp, LexicalNode::toBeDeletedFromList, tokenDepthAdmin, LexicalNode::tokenSeq, and LexicalNode::tokenSeqLength.
Referenced by processVector_processNodes().
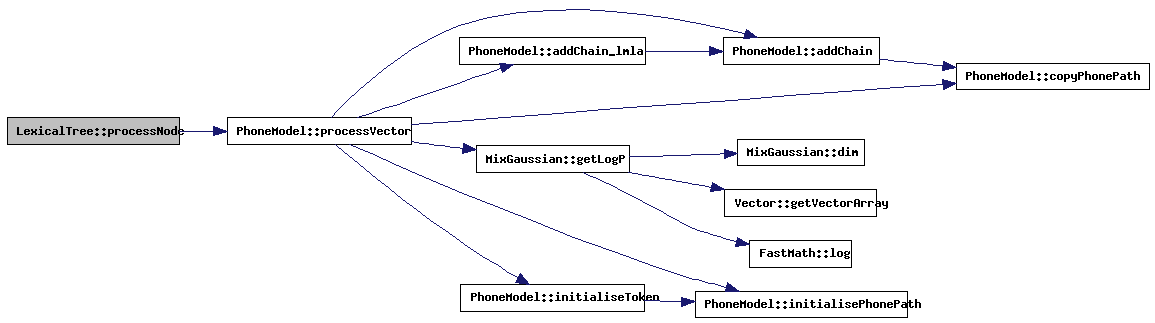
| void LexicalTree::processNodeOutput | ( | LexicalNode * | node | ) | [protected, virtual] |
This method handles all administration needed when a tokenlist enters the final node of a word (a leaf-node). The Word-Link-Record is updated and the tokens are passed to the next tree. This tree is the phase-in matrix of the lexical tree.
References PhoneModel::addChain(), addNodeToList(), WLRType::adminNext, bestL, WLRType::COMBlikelihood, PLRType::contextKey, LexicalNode::contextKey, copyLMHistory(), currentlyAligning, doPhoneAlignment, PhoneModel::getOutput(), PhoneModel::initialiseToken(), LexicalNode::inputToken, WLRType::isSil, WLRType::lattice, latticeGeneration, TokenType::likelihood, PLRType::likelihood, WLRType::lmHistory, WLRType::LMlikelihood, TokenType::lookAheadV, LexicalNode::modelID, WLRTypeList::nBest, WLRType::nBest, LexicalNode::next, TokenType::next, LexicalNode::nextTree, TokenType::path, WLRType::phoneAlignment, PLRType::phoneID, phoneModels, TokenType::phonePath, plrCount, PLRType::previous, WLRType::previous, processWord(), settings, setWlrNBest(), PLRType::stateOffset, WLRType::timeStamp, timeStamp, PLRType::timeStamp, LexicalNode::toBeDeletedFromList, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, touchWLRs(), wlrCount, wlrNBest, wlrStart, and LexicalNode::wordID.
Referenced by processVector_prune_processNodesOutput().
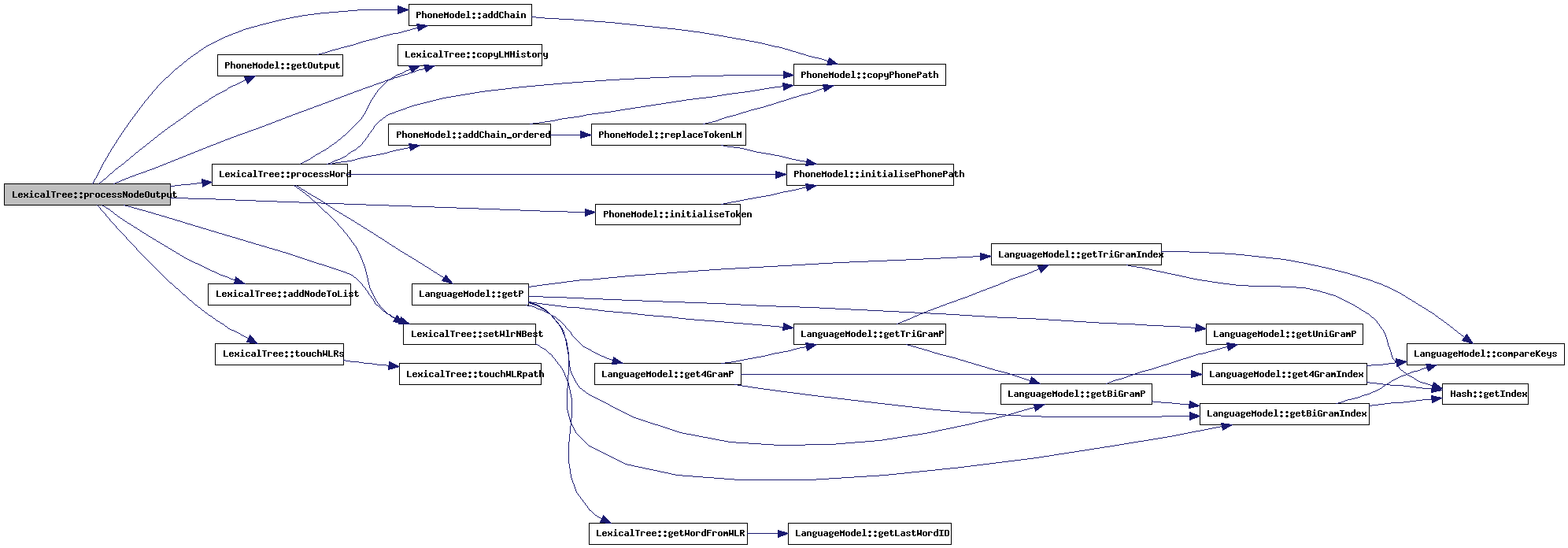
| void LexicalTree::processVector | ( | Vector ** | v, | |
| int | time | |||
| ) |
Inner loop method. Every time-frame this method is called with the observation-vector. The tasks in this method are split up to make it possible to analyse efficiency with gprof (profiler).
References bestL, currentlyAligning, latticeGeneration, latticeWordList, WLRTypeList::nBest, WLRTypeList::next, nrOfTokens, printTokenDistribution(), processVector_administrationCleanup(), processVector_LMLAReordering(), processVector_processNodes(), processVector_prune_processNodesOutput(), processVector_pruneLM(), DecoderSettings::prune_Lmla, settings, tdFile, timeStamp, and wlrNBest.
Referenced by Segmenter::segmentFeaturePool(), ShoutOnline::ShoutOnline(), and Whisper::Whisper().
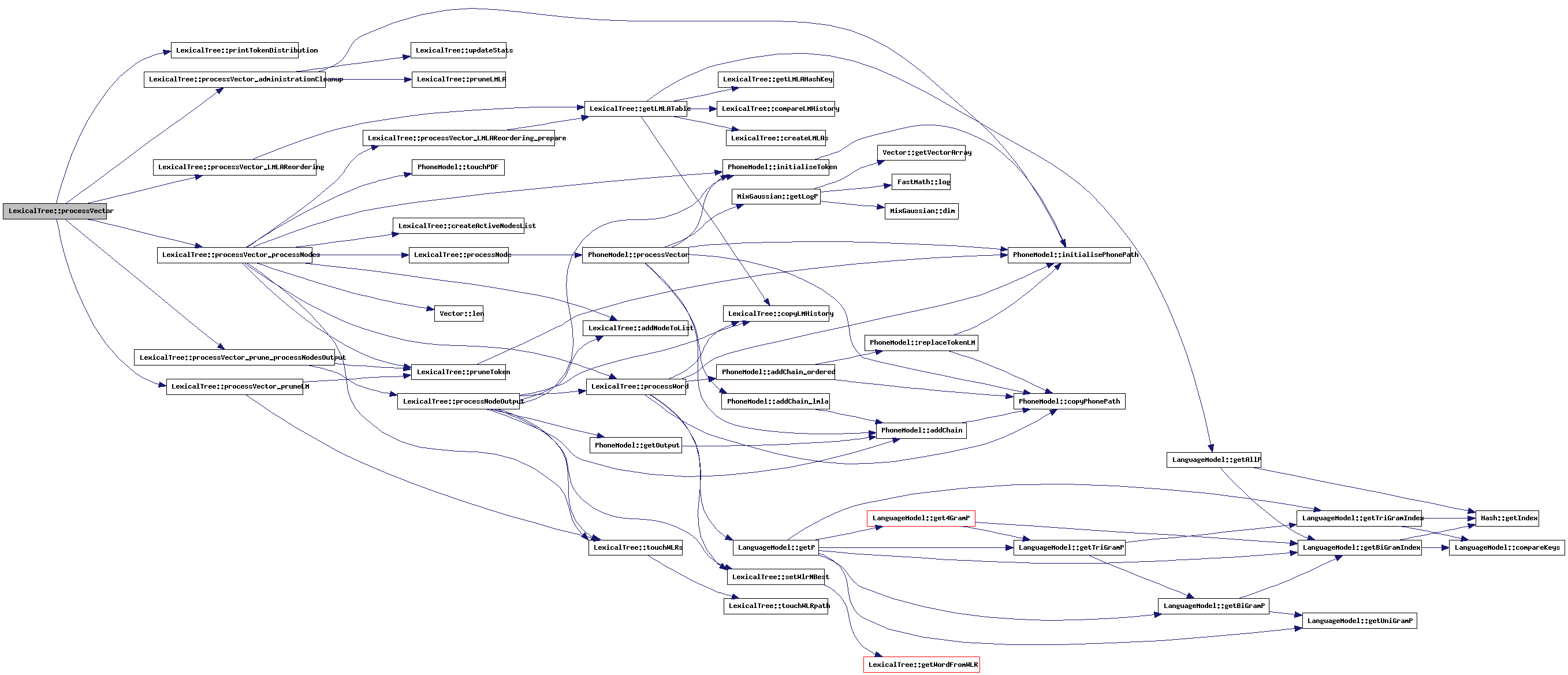
| void LexicalTree::processVector_administrationCleanup | ( | ) | [protected] |
Every time frame, some administrational data needs to be cleaned up.
References WLRType::adminNext, currentlyAligning, DecoderSettings::doBeam, doPhoneAlignment, PhoneModel::initialisePhonePath(), intervalTimer, WLRTypeList::nBest, WLRTypeList::next, nodeArray, LexicalNode::nodeIsActive, nodeListLength, WLRType::phoneAlignment, DecoderSettings::prune_Lmla, pruneLMLA(), settings, timeStamp, LexicalNode::toBeDeletedFromList, updateStats(), WLRType::usedAt, wlrCount, wlrNBest, and wlrStart.
Referenced by createLattice(), and processVector().

| void LexicalTree::processVector_grammar | ( | ) | [protected] |
For forced alignment, which uses basically a simple grammar instead of a lexical tree, the last node in the network, the endNode, contains the result of the decoding run. All tokens in this node should be contained. Therefore, the 'usedAt' flags need all to be kept up to date.
References endNode, LexicalNode::inputToken, TokenType::path, WLRType::previous, timeStamp, LexicalNode::tokenSeq, and WLRType::usedAt.
| void LexicalTree::processVector_LMLAReordering | ( | ) | [protected] |
This method will provide each input node (fan-in node) from treeStart with an LMLA table pointer. This pointer is either looked-up or created by getLMLATable().
References getLMLATable(), LexicalNode::inputToken, WLRType::lmHistory, lmla_condition_mutexDone, lmla_condition_threadDone, lmla_threadFinished, TokenType::lmLookAhead, TokenType::lookAheadV, TokenType::next, numberOfPhones, TokenType::path, and treeStart.
Referenced by processVector().

| void LexicalTree::processVector_LMLAReordering_prepare | ( | ) | [protected] |
References getLMLATable(), LexicalNode::inputToken, WLRType::lmHistory, TokenType::lmLookAhead, TokenType::lookAheadV, TokenType::next, numberOfPhones, TokenType::path, treeEnd, and treeStart.
Referenced by processVector_processNodes().

| void LexicalTree::processVector_processNodes | ( | Vector ** | v | ) | [protected] |
processVector_processNodes() is part of the inner-loop methods. It provides the observation Vector v to all nodes that are active.
The method consits of multiple steps:
- The active nodes list is extended with all nodes that are parralel nodes of a node that contains input tokens.
- The 'fan out' nodes, or end-nodes that contain input tokens are added to the list.
- All nodes are processed except for the nodes that contain wordIDs. The tokens for these nodes are already passed to the endNodes.
- All inputToken lists are deleted (they will be replaced by the new inputToken lists by the method processVector_prune_processNodesOutput() ).
References addNodeToList(), condition_mutexDone, condition_mutexStart, condition_threadDone, condition_threadStart, LexicalNode::contextKey, LexicalNode::contextPrev, createActiveNodesList(), currentlyAligning, DecoderSettings::doEndState, Thread_pdfCalculation_Data::doSecond, grammarStart, PhoneModel::initialiseToken(), LexicalNode::inputToken, Vector::len(), Thread_pdfCalculation_Data::length, Thread_pdfCalculation_Data::mixGaussian, LexicalNode::modelID, nodeArray, LexicalNode::nodeIsActive, nodeListLength, nrDataThreadsFinished, numberOfPhones, LexicalNode::parallel, pdfCount, pdfUpdateList, phoneModels, processNode(), processVector_LMLAReordering_prepare(), processWord(), DecoderSettings::prune_Lmla, DecoderSettings::prune_StateBeam, pruneToken(), Thread_pdfCalculation_Data::result, settings, threadMayStart, threadsRunning, Thread_pdfCalculation_Data::time, timeStamp, LexicalNode::toBeDeletedFromList, PhoneModel::touchPDF(), touchWLRs(), treeEnd, Thread_pdfCalculation_Data::vList, vList, and LexicalNode::wordID.
Referenced by processVector().

| void LexicalTree::processVector_prune_processNodesOutput | ( | ) | [protected] |
First pruning is performed:
- global beam pruning
- global histogram pruning
- state beam pruning (see paper)
- state histogram pruning Language Model Beam pruning is performed by processVector_pruneLM() Then the method determines which tokens should be passed to processNodeOutput().
References bestL, currentlyAligning, TokenType::likelihood, TokenType::next, nodeArray, nodeListLength, SearchStatistics::nrOfHistPruning, processNodeOutput(), DecoderSettings::prune_Beam, DecoderSettings::prune_Hist, DecoderSettings::prune_StateBeam, pruneToken(), sentenceStats, settings, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, and LexicalNode::wordID.
Referenced by processVector().
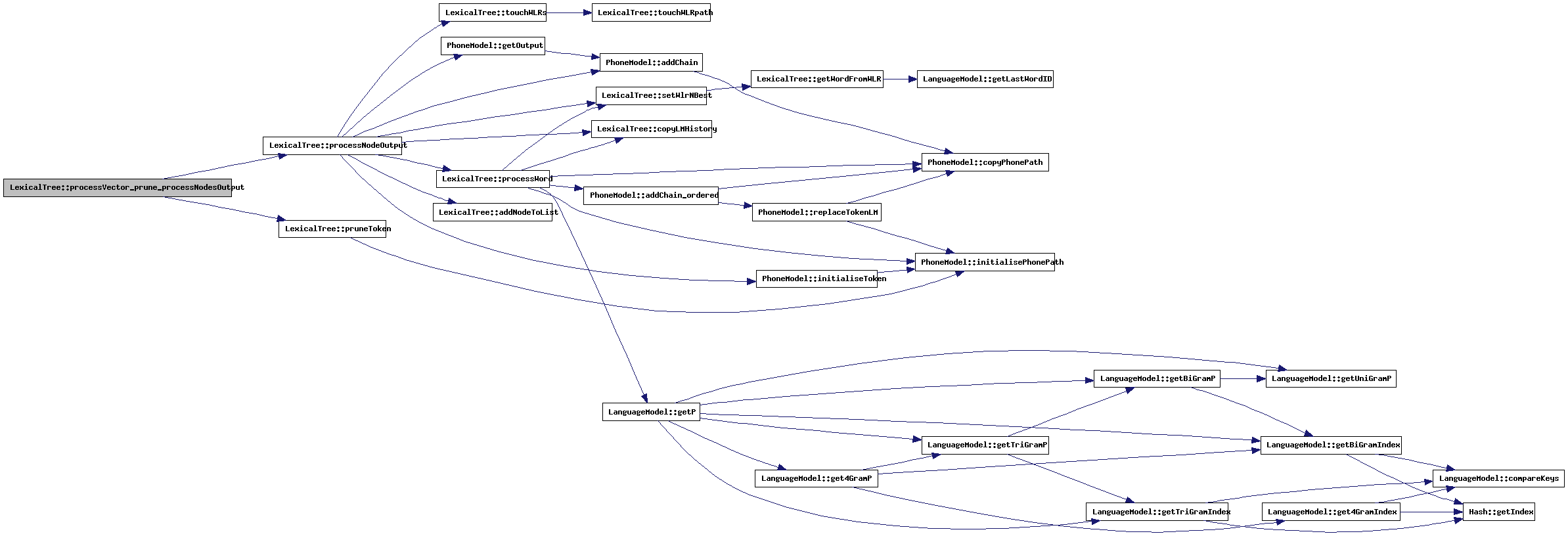
| void LexicalTree::processVector_pruneLM | ( | ) | [protected] |
All tokens that are in the phase-in matrix of the lexical tree at the point that this method is called, have just been assigned a new language model probability. At this point, a sharper beam-prune threshold can be used. This method applies this beam.
References DecoderSettings::doEndState, LexicalNode::inputToken, numberOfPhones, DecoderSettings::prune_EndStateBeam, pruneToken(), settings, touchWLRs(), and treeStart.
Referenced by processVector().

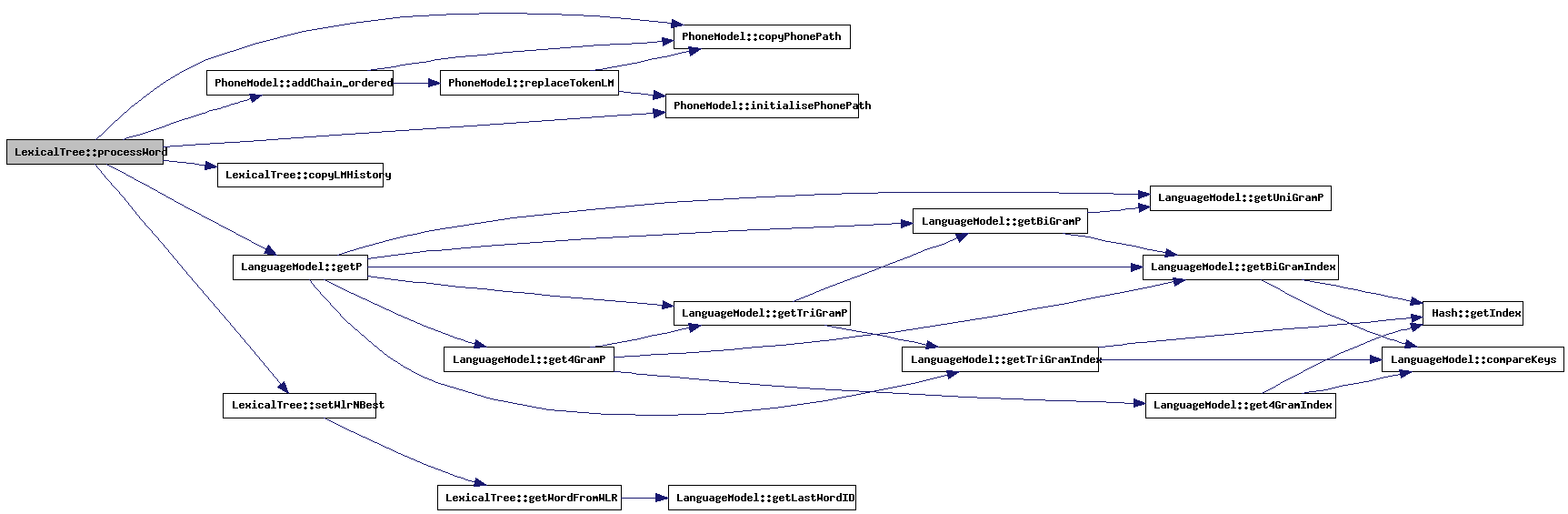
| void LexicalTree::processWord | ( | int | wordID, | |
| TokenType * | token, | |||
| char | isSil, | |||
| LexicalNode * | resultNode | |||
| ) | [protected] |
This method is called when a token has reached a leaf node. If available, the LM probability will be added. The word history of the token is updated (using a WLRType: Word Link Record) and the token is passed to the root of the tree.
When forced alignment is being performed, the token will be passed to the next tree, containing the next word to align.
References PhoneModel::addChain_ordered(), WLRType::adminNext, bestL, WLRType::COMBlikelihood, copyLMHistory(), PhoneModel::copyPhonePath(), currentlyAligning, doPhoneAlignment, LanguageModel::getP(), PhoneModel::initialisePhonePath(), LexicalNode::inputToken, WLRType::isSil, languageModel, WLRType::lattice, latticeGeneration, PLRType::likelihood, TokenType::likelihood, WLRType::lmHistory, WLRType::LMlikelihood, TokenType::lmLookAhead, TokenType::lookAheadV, WLRType::nBest, TokenType::next, TokenType::path, WLRType::phoneAlignment, TokenType::phonePath, WLRType::previous, settings, setWlrNBest(), timeStamp, WLRType::timeStamp, WLRType::usedAt, DecoderSettings::weights_LmScale, DecoderSettings::weights_TransPenalty, wlrCount, wlrStart, and wordLength.
Referenced by processNodeOutput(), and processVector_processNodes().
| void LexicalTree::pruneLMLA | ( | ) | [protected] |
This method will prune away all LMLA tables that are currently not being used. An LMLA is not used when there is no token in the PPT with the same LM history as the history of the LMLA table.
References LMLAGlobalListType::collissionTime, lmla_list, LMLAGlobalListType::lookAhead, LMLAGlobalListType::next, SearchStatistics::nrOfLMLATables_Temp, and sentenceStats.
Referenced by processVector_administrationCleanup().
| void LexicalTree::pruneToken | ( | TokenType ** | token, | |
| float | minLikelihood, | |||
| float | binSize = 0.0, |
|||
| int * | bins = NULL | |||
| ) | [protected] |
All tokens from the token list 'token' that have a likelihood less than 'minLikelihood' will be pruned by this method.
References bestL, doPhoneAlignment, PhoneModel::initialisePhonePath(), TokenType::likelihood, TokenType::next, TokenType::phonePath, and tokCount.
Referenced by processVector_processNodes(), processVector_prune_processNodesOutput(), and processVector_pruneLM().
| void LexicalTree::pruneWithMinBeam | ( | LexicalNode * | node, | |
| float | minLikelihood_0 | |||
| ) | [protected] |
| void LexicalTree::readTree | ( | LexicalNode * | node, | |
| FILE * | treeFile, | |||
| int | length | |||
| ) | [protected] |
This method recursively reads a binary PPT file.
References LexicalNode::contextNext, LexicalNode::contextPrev, WriteFileLittleBigEndian::freadEndianSafe(), LexicalNode::inputToken, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::nodeIsActive, LexicalNode::parallel, LexicalNode::toBeDeletedFromList, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, LexicalNode::wordID, and wordLength.
Referenced by LexicalTree().

| bool LexicalTree::safeBestRecognition | ( | bool | addEndOfSentence | ) |
This method will safe the word-path of the best recognition. This golden recognition is used for statistical analysis (blame assignment).
References analysisSettings, AnalysisSettings::beamCategories, AnalysisSettings::bestScore, AnalysisSettings::bestStateScore, AnalysisSettings::binDistr, WLRType::COMBlikelihood, AnalysisSettings::containsOOV, PLRType::contextKey, WLRTracker::contextNext, copyLMHistory(), PhoneModel::copyPhonePath(), AnalysisSettings::correctScore, AnalysisSettings::currentLMHist, doPhoneAlignment, AnalysisSettings::endStateActive, AnalysisSettings::errorRegionActive, findBestToken(), LanguageModel::getLastWordID(), LanguageModel::getP(), PhoneModel::initialisePhonePath(), WLRType::isSil, languageModel, WLRTracker::linkWord, WLRType::lmHistory, WLRType::LMlikelihood, AnalysisSettings::maxBeam, AnalysisSettings::maxEndStateBeam, AnalysisSettings::maxHistogram, AnalysisSettings::maxStateBeam, AnalysisSettings::maxStateHistogram, NBestList::noSilWords, NBestList::nrWords, numberOfPhones, TokenType::path, WLRType::phoneAlignment, WLRType::previous, AnalysisSettings::prunePathAnalyses, AnalysisSettings::prunePathAnalysesLength, AnalysisSettings::refStats, startOfSentenceWord, AnalysisSettings::stateRanking, WLRType::timeStamp, NBestList::totAM, NBestList::totLM, trackCount, WLRTracker::w, and WLRTracker::wordID.
Referenced by Whisper::Whisper().

| void LexicalTree::setAlignParallel | ( | ) |
FOR FUTURE USE! This message is called when a grammar needs parallel words. Currently this method is not used. It is only possible to do forced alignment without alternative paths.
References alignParallel.
| void LexicalTree::setAMs | ( | PhoneModel ** | models | ) |
The nodes of the lexical tree each contain modelIDs. These IDs point to acoustical models. With this method a set of models (in the 'models' array) is added to the system. The index of this model-array corresponds to the modelIDs of the tree.
References phoneModels.
Referenced by ShoutOnline::ShoutOnline(), and Whisper::Whisper().
| void LexicalTree::setDepthLevel | ( | LexicalNode * | node, | |
| int | phone, | |||
| int | depth | |||
| ) | [protected] |
This method will change the depth of all nodes to depth.
References LexicalNode::depth, LexicalNode::next, numberOfPhones, and LexicalNode::parallel.
Referenced by setTreeStartEndMatrix().
| bool LexicalTree::setForcedAlign | ( | const char * | string | ) |
The application may call this method repeadingly to make a forced alignment setting. The 'string' variable must be a single word.
If it this word is not in the vocabulary, this method will return false so that the application knows that the sentence (or blame region) has an OOV in it.
The nodes for each word will be added to the end of the alignment tree structure. If no alignment tree has been made yet, a new one will be formed.
Starting recognition will result in performing a forced alignment, until a NULL 'string' is send. In that case, the alingment tree structure is deleted and the normal PPT is used for recognition.
References addWordStringToAlignment(), borrowPhoneString(), LexicalNode::contextNext, LexicalNode::contextPrev, currentlyAligning, deleteTree(), LexicalNode::depth, endNode, endOfSentenceWord, grammarStart, initialiseSystem(), LexicalNode::inputToken, latticeWordList, latticeWordListLength, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::parallel, startOfSentenceWord, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, and LexicalNode::wordID.
Referenced by Whisper::Whisper().

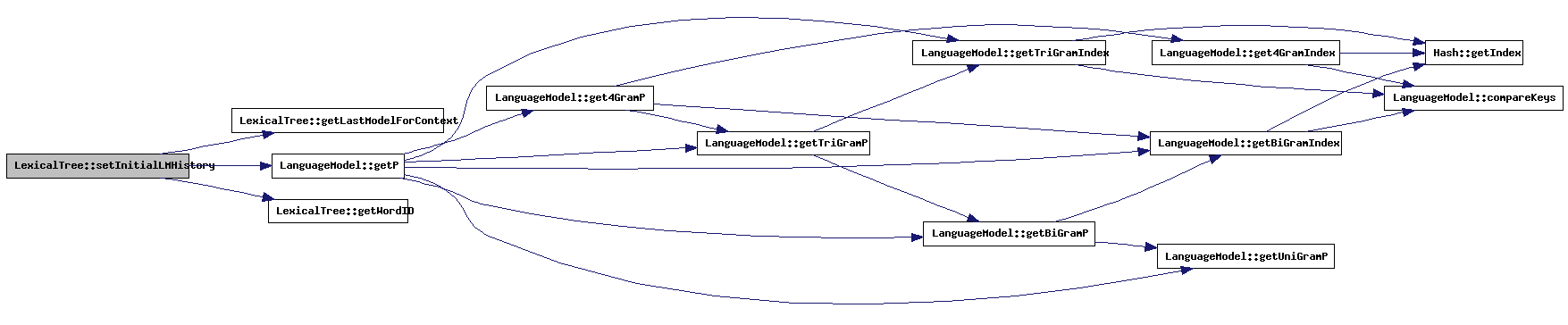
| void LexicalTree::setInitialLMHistory | ( | const char * | word1, | |
| const char * | word2 | |||
| ) |
The first token that is fed to the lexical tree root will need an initial language model history. This method changes the initial history to {word1,word2,-1}. This is needed for forced alignment tasks where the initial history is not equal to <sil>. (Used for blame assignment).
References getLastModelForContext(), LanguageModel::getP(), getWordID(), grammarStartContext, initialLMHist, languageModel, numberOfPhones, startOfSentenceWord, and treeStart.
Referenced by Whisper::Whisper().
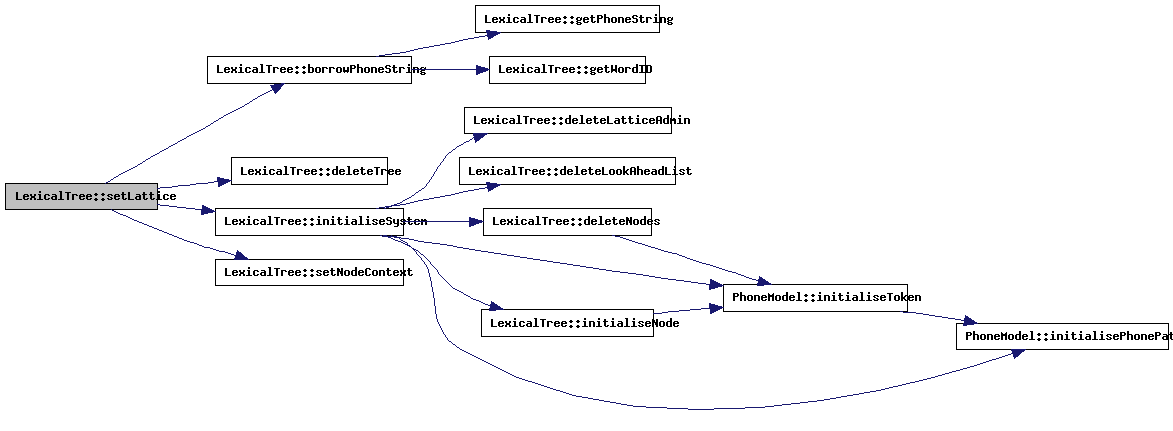
| void LexicalTree::setLattice | ( | FILE * | latFile | ) |
This method will create a lattice structure for rescoring.
References borrowPhoneString(), LexicalNode::compressedTreeIndex, LexicalNode::contextKey, LexicalNode::contextNext, LexicalNode::contextPrev, currentlyAligning, deleteTree(), LexicalNode::depth, endNode, endOfSentenceWord, grammarStart, grammarStartContext, initialiseSystem(), LexicalNode::inputToken, latticeWordList, latticeWordListLength, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::nodeIsActive, LexicalNode::parallel, setNodeContext(), LexicalNode::toBeDeletedFromList, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, and LexicalNode::wordID.
Referenced by ShoutOnline::ShoutOnline(), and Whisper::Whisper().
| void LexicalTree::setLatticeGeneration | ( | bool | setting | ) |
Determines if we should create administration for lattices...
References latticeGeneration.
Referenced by Whisper::Whisper().
| void LexicalTree::setLM | ( | LanguageModel * | lm | ) |
The application can add a LanguageModel to the lexical tree system. If a model is added, when tokens are re-propagated to the root of the tree, the language model probability is calculated and added to the likelihood of the token. Also if the compiler switch LMLA is set, this LM will be used to calculate LMLA tables.
References LanguageModel::getNumberOfWords(), languageModel, and numberOfWords.
Referenced by ShoutOnline::ShoutOnline(), and Whisper::Whisper().
| void LexicalTree::setNodeContext | ( | LexicalNode * | node, | |
| int | leftContext | |||
| ) | [protected] |
- Todo:
- Docs
References LexicalNode::contextKey, LexicalNode::contextNext, LexicalNode::contextPrev, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, numberOfPhones, and LexicalNode::parallel.
Referenced by setLattice().
| void LexicalTree::setNodeLocationPars | ( | LexicalNode * | node, | |
| bool | fromParallel | |||
| ) | [protected] |
Each node in the tree contains a number of parameters that give information on the location of the node in the tree. These parameters are set with this method.
The most important parameter is compressedTreeIndex. This parameter defines if a node is also part of the 'compressed tree'.
References LexicalNode::compressedTreeIndex, LexicalNode::contextKey, LexicalNode::contextNext, LexicalNode::contextPrev, LexicalNode::next, numberOfCompressedNodes, numberOfPhones, LexicalNode::parallel, and LexicalNode::wordID.
Referenced by setTreeStartEndMatrix().
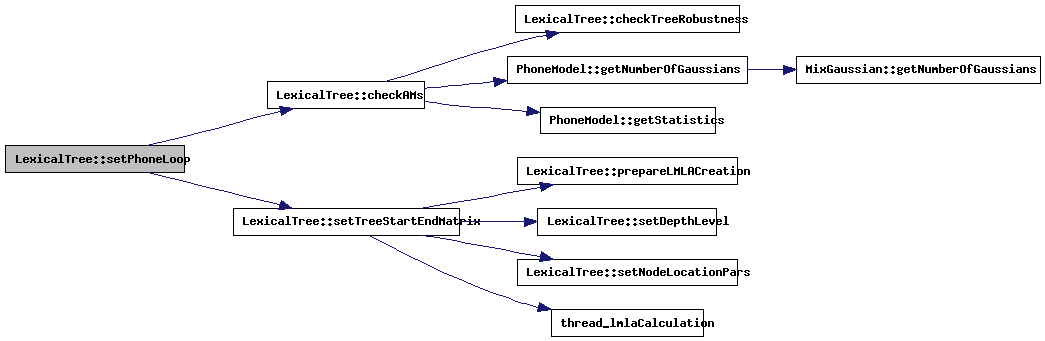
| void LexicalTree::setPhoneLoop | ( | int | nrP, | |
| PhoneModel ** | models | |||
| ) |
Uses the AM to make a phone-loop lexical tree...
References bestL, checkAMs(), LexicalNode::contextNext, LexicalNode::contextPrev, currentlyAligning, endNode, endOfSentenceWord, grammarStart, grammarStartContext, LexicalNode::inputToken, languageModel, latticeAdmin, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::nodeIsActive, nodeList, numberOfPhones, numberOfWords, LexicalNode::parallel, phoneModels, setTreeStartEndMatrix(), startOfSentenceWord, timeStamp, LexicalNode::toBeDeletedFromList, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, treeEnd, treeStart, vocabulary, wlrNBest, wlrStart, LexicalNode::wordID, and wordLength.
Referenced by Whisper::Whisper().
| void LexicalTree::setPhoneLoopConfidence | ( | float * | phoneConf, | |
| int | offset = 0 | |||
| ) |
Sets the confidence array of the phone loop. This is used for confidence measuring. Currently, the confidence is only printed on the screen. Analysis is done externally...
References phoneLoopConfidence, and phoneLoopConfidenceOffset.
| void LexicalTree::setTokenDistributionFile | ( | FILE * | tdF | ) |
Sets the token-distribution file handler for the current utterence. Each time frame of a recognition (not of a forced alignment), the distribution file will be updated.
References numberOfPhones, and tdFile.
| void LexicalTree::setTreeStartEndMatrix | ( | ) | [protected] |
The tree skeleton has been constructed. Now finish the start- and end-matrices...
References biggestNodeDepth, LexicalNode::compressedTreeIndex, LexicalNode::contextKey, LexicalNode::contextNext, LexicalNode::contextPrev, LexicalNode::depth, Thread_LMLACalculation_Data::fastCompressedTree, fastCompressedTree, initialLMHist, LexicalNode::inputToken, lmla_list, lmla_thread, LexicalNode::modelID, LexicalNode::next, LexicalNode::nextTree, LexicalNode::nodeIsActive, Thread_LMLACalculation_Data::numberOfCompressedNodes, numberOfCompressedNodes, numberOfPhones, LexicalNode::parallel, prepareLMLACreation(), setDepthLevel(), setNodeLocationPars(), startOfSentenceWord, thread_lmlaCalculation(), LexicalNode::toBeDeletedFromList, tokenDepthAdmin, LexicalNode::tokenSeq, LexicalNode::tokenSeqLength, treeEnd, treeStart, and LexicalNode::wordID.
Referenced by LexicalTree(), and setPhoneLoop().
| void LexicalTree::setWlrNBest | ( | WLRType * | wlr | ) | [protected] |
References WLRType::COMBlikelihood, getWordFromWLR(), WLRTypeList::nBest, WLRType::timeStamp, and wlrNBest.
Referenced by processNodeOutput(), and processWord().

| void LexicalTree::sortLatticePaths | ( | LatticeNode * | l | ) | [protected] |
- Todo:
- DOCS
References WLRType::COMBlikelihood, WLRList::next, LatticeNode::outArcs, and WLRList::wlr.
Referenced by printLMParStats().
| void LexicalTree::storePLConfidence | ( | int | time | ) |
For the phone-loop: stores the best likelihood minus the number of phones times the transition penalty..
References phoneLoopConfidence.
| void LexicalTree::testArticulatory | ( | ArticulatoryStream * | s | ) |
References myArtStream.
| void LexicalTree::touchWLRpath | ( | WLRType * | w | ) | [protected] |
References WLRType::nBest, WLRType::previous, timeStamp, and WLRType::usedAt.
Referenced by touchWLRs().
| void LexicalTree::touchWLRs | ( | TokenType * | token | ) | [protected] |
In order to know if a Word Link Record is still being used by any token (the tokens using a particular WLR may be pruned away), this method will "touch" all WLRs that are in the token list 'token'.
Touching the WLRs every few iterations is faster than checking if all available WLRs are still valid all the time.
References TokenType::next, TokenType::path, and touchWLRpath().
Referenced by createLattice(), processNodeOutput(), processVector_processNodes(), and processVector_pruneLM().

| void LexicalTree::updateGlobalStats | ( | ) |
This method updates the global lexical tree statistics. Global statistiscs are statistics on all recognition tasks in one session (like average amount of nodes needed for all utterences).
References globalStats, SearchStatistics::nrOfActiveNodes, SearchStatistics::nrOfActiveNodes_Max, SearchStatistics::nrOfActiveNodes_Prev, SearchStatistics::nrOfActiveTokens, SearchStatistics::nrOfActiveTokens_Max, SearchStatistics::nrOfActiveTokens_Prev, SearchStatistics::nrOfCleanUps, SearchStatistics::nrOfLMLATables, SearchStatistics::nrOfLMLATables_Max, SearchStatistics::nrOfLMLATables_Prev, and sentenceStats.
| void LexicalTree::updateStats | ( | ) | [protected] |
This method updates the internal lexical tree statistics. Internal statistiscs are statistics on one recognition task of a session (like average amount of nodes needed for the current utterence).
References LexicalNode::inputToken, LexicalNodeList::next, TokenType::next, LexicalNodeList::node, nodeList, SearchStatistics::nrOfActiveNodes, SearchStatistics::nrOfActiveNodes_Max, SearchStatistics::nrOfActiveNodes_Prev, SearchStatistics::nrOfActiveTokens, SearchStatistics::nrOfActiveTokens_Max, SearchStatistics::nrOfActiveTokens_Prev, SearchStatistics::nrOfCleanUps, SearchStatistics::nrOfLMLATables, SearchStatistics::nrOfLMLATables_Max, SearchStatistics::nrOfLMLATables_Prev, SearchStatistics::nrOfLMLATables_Temp, sentenceStats, LexicalNode::tokenSeq, and LexicalNode::tokenSeqLength.
Referenced by processVector_administrationCleanup().
Member Data Documentation
bool LexicalTree::alignParallel [protected] |
int LexicalTree::analyse_deletions[NUMBER_OF_BLAME_CLUSTERS] [protected] |
Referenced by errorAnalysis(), LexicalTree(), and printFinalSettings().
int LexicalTree::analyse_insertions[NUMBER_OF_BLAME_CLUSTERS] [protected] |
Referenced by errorAnalysis(), LexicalTree(), and printFinalSettings().
int LexicalTree::analyse_substitutions[NUMBER_OF_BLAME_CLUSTERS] [protected] |
Referenced by errorAnalysis(), LexicalTree(), and printFinalSettings().
int LexicalTree::analyse_totRefWords [protected] |
Referenced by errorAnalysis(), LexicalTree(), and printFinalSettings().
AnalysisSettings* LexicalTree::analysisSettings [protected] |
Used to keep track of analysis administration (blame assignment).
Referenced by calcErrorRegionStats(), errorAnalysis(), getBestRecognition(), LexicalTree(), printFinalSettings(), printLMParStats(), safeBestRecognition(), and ~LexicalTree().
float LexicalTree::bestL [protected] |
The likelihood of token 'bestToken'.
Referenced by initialiseSystem(), LexicalTree(), processNode(), processNodeOutput(), processVector(), processVector_prune_processNodesOutput(), processWord(), pruneToken(), and setPhoneLoop().
WLRType* LexicalTree::bestRecPath [protected] |
Used for adaptation, it would be inconvenient to find the best token each frame.
Referenced by adaptAMs(), getBestRecognition(), and initialiseSystem().
TokenType* LexicalTree::bestToken [protected] |
A pointer to the best token in the tree.
int LexicalTree::biggestNodeDepth [protected] |
Referenced by printTokenDistribution(), and setTreeStartEndMatrix().
int LexicalTree::blameAssingment[NUMBER_OF_BLAME_CLUSTERS] [protected] |
Referenced by errorAnalysis(), LexicalTree(), and printFinalSettings().
LexicalNode** LexicalTree::borrowWordList [protected] |
Referenced by borrowPhoneString(), LexicalTree(), and ~LexicalTree().
bool LexicalTree::currentlyAligning [protected] |
If TRUE, the system will be aligning. Otherwise it does LVCSR.
Referenced by addForcedAlignOOV(), Segmenter::createLexicalTree(), findBestToken(), LexicalTree(), processNode(), processNodeOutput(), processVector(), processVector_administrationCleanup(), processVector_processNodes(), processVector_prune_processNodesOutput(), processWord(), setForcedAlign(), setLattice(), setPhoneLoop(), and ~LexicalTree().
LexicalNode* LexicalTree::endNode [protected] |
The last node. Only used for forced-align grammars.
Referenced by addForcedAlignOOV(), addWordStringToAlignment(), findBestToken(), getBestGrammarEndToken(), initialiseSystem(), latticeBaumWelch_backward(), latticeBaumWelch_initBackward(), LexicalTree(), processVector_grammar(), setForcedAlign(), setLattice(), setPhoneLoop(), and ~LexicalTree().
int LexicalTree::endOfSentenceWord [protected] |
The index of the </s> word.
Referenced by addForcedAlignOOV(), addWordStringToAlignment(), Segmenter::createLexicalTree(), findBestToken(), LexicalTree(), setForcedAlign(), setLattice(), and setPhoneLoop().
FastCompressedTree* LexicalTree::fastCompressedTree [protected] |
Referenced by createLMLAs(), LexicalTree(), prepareLMLACreation(), setTreeStartEndMatrix(), and ~LexicalTree().
SearchStatistics LexicalTree::globalStats [protected] |
Referenced by printFinalSettings(), printInitialSettings(), and updateGlobalStats().
LexicalNode* LexicalTree::grammarStart [protected] |
The start of the tree or (forced-align) grammar.
Referenced by addWordStringToAlignment(), alignmentIsEmpty(), Segmenter::createLexicalTree(), Segmenter::createSegments(), findBestToken(), getAlignmentString(), initialiseSystem(), initialiseTree(), latticeBaumWelch_backward(), latticeBaumWelch_calculatePosteriors(), latticeBaumWelch_forward(), latticeBaumWelch_initForward(), latticeBaumWelch_mmi_accumulatorsPosteriors(), latticeBaumWelch_numberNodes(), latticeBaumWelch_printPosteriors(), latticeBaumWelch_setLikelihoods(), LexicalTree(), processVector_processNodes(), setForcedAlign(), setLattice(), setPhoneLoop(), and ~LexicalTree().
int LexicalTree::grammarStartContext [protected] |
Initial left context when starting the system (for forced-align).
Referenced by addWordStringToAlignment(), initialiseTree(), LexicalTree(), setInitialLMHistory(), setLattice(), and setPhoneLoop().
int LexicalTree::initialLMHist[LM_NGRAM_DEPTH] [protected] |
The history words at the start of a new utterence.
Referenced by initialiseTree(), LexicalTree(), printLMParStats(), setInitialLMHistory(), and setTreeStartEndMatrix().
int LexicalTree::intervalTimer [protected] |
Referenced by initialiseSystem(), and processVector_administrationCleanup().
LanguageModel* LexicalTree::languageModel [protected] |
The used language model.
Referenced by calcErrorRegionStats(), createLatticeLMRescoring(), createLatticeNodeGroups(), findBestToken(), getBestIDSequence(), getBestPath(), getLMLATable(), getWordFromWLR(), LexicalTree(), processWord(), safeBestRecognition(), setInitialLMHistory(), setLM(), setPhoneLoop(), Train_Segmenter::Train_Segmenter(), and Train_Segmenter::trainIteration().
LatticeNode* LexicalTree::latticeAdmin [protected] |
A list of all lattice nodes.
Referenced by createLattice(), createLatticeNodeGroups(), deleteLatticeAdmin(), findLatticeNodes(), lattice_removeDoubleArcs(), LexicalTree(), printLattice(), printLMParStats(), printNBestList(), and setPhoneLoop().
bool LexicalTree::latticeGeneration [protected] |
Referenced by LexicalTree(), processNodeOutput(), processVector(), processWord(), and setLatticeGeneration().
int LexicalTree::latticeL [protected] |
Referenced by createLattice(), and printLattice().
int LexicalTree::latticeN [protected] |
Referenced by createLattice(), and printLattice().
LexicalNode** LexicalTree::latticeWordList [protected] |
Referenced by findBestToken(), initialiseNode(), initialiseTree(), LexicalTree(), processVector(), setForcedAlign(), setLattice(), and ~LexicalTree().
int LexicalTree::latticeWordListLength [protected] |
Referenced by setForcedAlign(), setLattice(), and ~LexicalTree().
LMLAGlobalListType* LexicalTree::lmla_list[LMLA_CACHE] [protected] |
The LMLA data structure. (see paper).
Referenced by deleteLookAheadList(), getLMLATable(), LexicalTree(), pruneLMLA(), and setTreeStartEndMatrix().
LMLAGlobalListType* LexicalTree::lookAheadUnigram [protected] |
Referenced by deleteLookAheadList(), getLMLATable(), and LexicalTree().
ArticulatoryStream* LexicalTree::myArtStream [protected] |
Referenced by getBestRecognition(), getPhoneAlignment(), and testArticulatory().
LexicalNode** LexicalTree::nodeArray [protected] |
LexicalNodeList* LexicalTree::nodeList [protected] |
A list of all active nodes for the following time frame (so that the tree does not have to be searched).
Referenced by addNodeToList(), createActiveNodesList(), initialiseSystem(), LexicalTree(), setPhoneLoop(), updateStats(), and ~LexicalTree().
int LexicalTree::nodeListLength [protected] |
int LexicalTree::nrOfTokens [protected] |
int LexicalTree::numberOfCompressedNodes [protected] |
Referenced by createLMLAs(), getLMLATable(), setNodeLocationPars(), and setTreeStartEndMatrix().
int LexicalTree::numberOfPhones [protected] |
The number of acoustic models types (not the number in the tree).
Referenced by Adapt_Segmenter::Adapt_Segmenter(), addWordStringToAlignment(), borrowPhoneString(), checkAMs(), checkTreeRobustness(), Segmenter::createLexicalTree(), Train_Segmenter::createOverlapTree(), findBestToken(), findCorrectNode(), getPhoneAlignment(), initialiseSystem(), initialiseTree(), LexicalTree(), Adapt_Segmenter::proceedMerge(), processVector_LMLAReordering(), processVector_LMLAReordering_prepare(), processVector_processNodes(), processVector_pruneLM(), safeBestRecognition(), Segmenter::Segmenter(), setDepthLevel(), setInitialLMHistory(), setNodeContext(), setNodeLocationPars(), setPhoneLoop(), setTokenDistributionFile(), setTreeStartEndMatrix(), Shout_dct2lextree::Shout_dct2lextree(), ShoutSegment::ShoutSegment(), Train_Segmenter::Train_Segmenter(), ~LexicalTree(), Segmenter::~Segmenter(), and Train_Segmenter::~Train_Segmenter().
int LexicalTree::numberOfWords [protected] |
The number of words in the DCT.
Referenced by borrowPhoneString(), Train_Segmenter::createInitialModels(), Train_Segmenter::createOverlapTree(), getLMLATable(), getNumberOfWords(), Train_Segmenter::getOverlap(), getWordID(), LexicalTree(), Train_Segmenter::loadClusters(), Train_Segmenter::mergeClusters(), setLM(), setPhoneLoop(), Shout_dct2lextree::Shout_dct2lextree(), Train_Segmenter::startMergeIteration(), Train_Segmenter::train(), Train_Segmenter::Train_Segmenter(), Train_Segmenter::trainClusters(), Train_Segmenter::trainIteration(), Train_Segmenter::writePosteriors(), and ~LexicalTree().
FILE* LexicalTree::outputFile [protected] |
Output hyp file.
Referenced by checkAMs(), errorAnalysis(), findBestToken(), getBestPath(), getBestRecognition(), getPhoneAlignment(), latticeBaumWelch_printPosteriors(), LexicalTree(), printErrorString(), printFinalSettings(), printInitialSettings(), printLMParStats(), printNBestList(), and printWordPronunciation().
MixGaussian** LexicalTree::pdfUpdateList [protected] |
Referenced by processVector_processNodes().
float* LexicalTree::phoneLoopConfidence [protected] |
Referenced by getBestPath(), getPhoneAlignment(), LexicalTree(), setPhoneLoopConfidence(), and storePLConfidence().
int LexicalTree::phoneLoopConfidenceOffset [protected] |
Referenced by getBestPath(), getPhoneAlignment(), LexicalTree(), and setPhoneLoopConfidence().
PhoneModel** LexicalTree::phoneModels [protected] |
An array of all distinct acoustic models.
Referenced by adaptAMs(), checkAMs(), Segmenter::createLexicalTree(), ShoutSegment::doSAD_noGarbage(), getAlignmentString(), getPhoneAlignment(), latticeBaumWelch_backward(), latticeBaumWelch_calculatePosteriors(), latticeBaumWelch_forward(), latticeBaumWelch_mmi_accumulatorsPosteriors(), latticeBaumWelch_setLikelihoods(), printWordPronunciation(), processNode(), processNodeOutput(), processVector_processNodes(), Segmenter::Segmenter(), setAMs(), setPhoneLoop(), ShoutSegment::ShoutSegment(), Train_Segmenter::Train_Segmenter(), Segmenter::~Segmenter(), and Train_Segmenter::~Train_Segmenter().
SearchStatistics LexicalTree::sentenceStats [protected] |
DecoderSettings LexicalTree::settings [protected] |
Referenced by calcErrorRegionStats(), createLatticeNodeGroups(), errorAnalysis(), findBestToken(), getBestRecognition(), getLMLATable(), getPhoneAlignment(), initialiseSystem(), LexicalTree(), overwritePrunePars(), overwriteWeightPars(), printInitialSettings(), processNode(), processNodeOutput(), processVector(), processVector_administrationCleanup(), processVector_processNodes(), processVector_prune_processNodesOutput(), processVector_pruneLM(), and processWord().
int LexicalTree::startOfSentenceWord [protected] |
The index of the <s> word.
Referenced by calcErrorRegionStats(), createLattice(), createLatticeLMRescoring(), createLatticeNodeGroups(), Segmenter::createLexicalTree(), errorAnalysis(), getBestIDSequence(), getBestPath(), getWordFromWLR(), lattice_copyNonSilArcs(), LexicalTree(), printLattice(), safeBestRecognition(), setForcedAlign(), setInitialLMHistory(), setPhoneLoop(), and setTreeStartEndMatrix().
int LexicalTree::startTime [protected] |
Referenced by createLattice(), getBestIDSequence(), getBestPath(), initialiseTree(), and LexicalTree().
FILE* LexicalTree::tdFile [protected] |
Token Distribution File.
Referenced by LexicalTree(), printTokenDistribution(), processNode(), processVector(), and setTokenDistributionFile().
int LexicalTree::threadsRunning [protected] |
Referenced by processVector_processNodes().
int LexicalTree::timeStamp [protected] |
int* LexicalTree::tokenDepthAdmin [protected] |
Referenced by LexicalTree(), printTokenDistribution(), processNode(), setTreeStartEndMatrix(), and ~LexicalTree().
int LexicalTree::totCategories[3] [protected] |
Referenced by LexicalTree().
float* LexicalTree::transitionPenalty [protected] |
The transition penalty and short-word-penalty can be calculated once in the constructor.
Referenced by getLMLATable(), LexicalTree(), and ~LexicalTree().
LexicalNode** LexicalTree::treeEnd [protected] |
The matrix of end-of-word nodes (so called phase-out).
Referenced by findCorrectNode(), initialiseSystem(), LexicalTree(), processVector_LMLAReordering_prepare(), processVector_processNodes(), setPhoneLoop(), setTreeStartEndMatrix(), and ~LexicalTree().
LexicalNode** LexicalTree::treeStart [protected] |
The matrix of start-of-word nodes (phase-in).
Referenced by borrowPhoneString(), checkAMs(), findBestToken(), findCorrectNode(), initialiseSystem(), initialiseTree(), LexicalTree(), processVector_LMLAReordering(), processVector_LMLAReordering_prepare(), processVector_pruneLM(), setInitialLMHistory(), setPhoneLoop(), setTreeStartEndMatrix(), Shout_dct2lextree::Shout_dct2lextree(), and ~LexicalTree().
double* LexicalTree::vList [protected] |
Referenced by LexicalTree(), and processVector_processNodes().
char** LexicalTree::vocabulary [protected] |
The vocabulary.
Referenced by errorAnalysis(), getBestPath(), Train_Segmenter::getOverlap(), getWord(), getWordID(), LexicalTree(), printLattice(), printNBestList(), setPhoneLoop(), Shout_dct2lextree::Shout_dct2lextree(), Train_Segmenter::Train_Segmenter(), and ~LexicalTree().
WLRTypeList* LexicalTree::wlrNBest [protected] |
Each time frame the N-Best wlrs are marked as being one of the best!
Referenced by initialiseSystem(), LexicalTree(), processNodeOutput(), processVector(), processVector_administrationCleanup(), setPhoneLoop(), and setWlrNBest().
WLRType* LexicalTree::wlrStart [protected] |
The first Word-Link-Record (linked together in WLRType).
Referenced by initialiseSystem(), initialiseTree(), LexicalTree(), processNodeOutput(), processVector_administrationCleanup(), processWord(), and setPhoneLoop().
int* LexicalTree::wordLength [protected] |
Referenced by LexicalTree(), processWord(), readTree(), and setPhoneLoop().