TrainPhoneModel Class Reference
With help of this class, the acoustic models are trained. More...
Public Member Functions | |
| TrainPhoneModel (const char *n, int contextLeft, int contextRight, bool isSil, int dim, FeaturePoolInfo *infoBlock=NULL) | |
| TrainPhoneModel (MixGaussian *gmm, double trans, const char *name) | |
| TrainPhoneModel (TrainPhoneModel *model1, TrainPhoneModel *model2, int maxGaussians=-1) | |
| TrainPhoneModel (TrainPhoneModel *model1, TrainPhoneModel *model2, double rate) | |
| TrainPhoneModel (TrainPhoneModel *orgModel, int shiftLeftRight=0) | |
| TrainPhoneModel (FILE *inFile, int dim, FeaturePoolInfo *infoBlock=NULL) | |
| ~TrainPhoneModel () | |
| void | trainMMI (FILE *fileEnum, FILE *fileDenom) |
| void | doNotuseBordersForTraining (bool useBordersNot) |
| int | maxNrOfGaussians () |
| double | getTrainSilP (int useLabel=-1, int useSegmentation=-1, FeaturePool *usePool=NULL) |
| void | adapt_setAcTrain (int useLabel=-1, int useSegmentation=-1, FeaturePool *usePool=NULL) |
| bool | readModel (FILE *inFile) |
| void | writeSAT (FILE *outFile) |
| void | appendSAT (FILE *outFile) |
| double | finishSAT () |
| void | setDecisionMatrix (int numberOfModels, int numberOfRules, int *dMatrix) |
| void | setTrainingData (FeaturePool *fp, int segmentationID, int labelID, int guestID=-1, int tSilP=100, int tSilMax=-1) |
| double | train (int maxGaussians, bool isSil, bool neverPrune=false, Vector **trainDiscr=NULL, Vector *trainDiscrMask=NULL, PhoneModel *doSAT=NULL, bool doFastTraining=false) |
| double | getCoSim (TrainPhoneModel *t1, TrainPhoneModel *t2) |
| double | getKLDistance (TrainPhoneModel *t2) |
| double | getNormDistance () |
| void | startCount () |
| void | stopCount () |
| void | count (Vector *observation) |
| int | getDominantGaussian () |
| void | addCountedGaussians (TrainPhoneModel *source, int nmbr) |
| void | moveModelGaussians (TrainPhoneModel *model, double factor) |
| void | addGaussian (Vector *v) |
| void | normalize () |
| void | setMaxGaussians (int maxGaussians) |
| double | getClusterP (Vector *observation) |
| void | fillDistanceArray (int *distA) |
Protected Member Functions | |
| double | baumWelch (int trainWhat, PhoneModel *doSat=NULL) |
| double | viterbi (int trainWhat) |
| double | getSilP (int useLabel, int useSegmentation, FeaturePool *usePool) |
Protected Attributes | |
| int | trainSilP |
| int | trainSilMax |
| int * | decision_Matrix |
| int | decision_numberOfModels |
| int | decision_numberOfRules |
| int | totalLength |
| FeaturePool * | trainingPool |
| int | trainingSegment |
| int | trainingLabel |
| int | guestTrainingLabel |
| FeaturePoolInfo * | channelInfoBlock |
| bool | trainWithoutBorders |
Detailed Description
With help of this class, the acoustic models are trained.Before training the HMM, training samples need to be added to the system, using the addTrainingSample() method. Once all samples are added the HMM may be trained with the train() method. It is possible to either receive and send the model over a socket connection (also see the Socket_Server and Socket_Client classes) with receiveModel() and sendModel() or write the model to disk with writeModel(). The viterbi() method is used to determine the best path for one training sample. During use of the models (see the PhoneModel class), the viterbi token passing, a special form of viterbi, is used.
Constructor & Destructor Documentation
| TrainPhoneModel::TrainPhoneModel | ( | const char * | n, | |
| int | contextLeft, | |||
| int | contextRight, | |||
| bool | isSil, | |||
| int | dim, | |||
| FeaturePoolInfo * | infoBlock = NULL | |||
| ) |
This constructor is used to create an empty training model. The name (input parameter) of the phone is stored in the statistics structure. The number of gaussians per state is set to one.
References channelInfoBlock, decision_Matrix, PhoneModel::dimensions, ModelStats::frameMeanLikelihood, guestTrainingLabel, ModelStats::isSil, ModelStats::likelihood, ModelStats::maxNrOfContexts, PhoneModel::mixtureSetData, ModelStats::name, ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, FeaturePoolInfo::numberOfChannels, MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, PhoneModel::timeStamp, trainingLabel, trainingPool, trainingSegment, trainSilMax, trainSilP, trainWithoutBorders, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.
| TrainPhoneModel::TrainPhoneModel | ( | MixGaussian * | gmm, | |
| double | trans, | |||
| const char * | name | |||
| ) |
This constructor is used to create a new PhoneModel object with only one state (SIL), outgoing transition probability trans and GMM gmm. (used by Train_Speaker_Segmenter)
References channelInfoBlock, decision_Matrix, MixGaussian::dim(), PhoneModel::dimensions, ModelStats::frameMeanLikelihood, MixGaussian::getNumberOfGaussians(), guestTrainingLabel, PhoneModel::isSil, ModelStats::isSil, ModelStats::likelihood, FastMath::log(), ModelStats::maxNrOfContexts, PhoneModel::mixtureSetData, ModelStats::name, ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, PhoneModel::timeStamp, trainingLabel, trainingPool, trainingSegment, trainSilMax, trainSilP, trainWithoutBorders, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.

| TrainPhoneModel::TrainPhoneModel | ( | TrainPhoneModel * | model1, | |
| TrainPhoneModel * | model2, | |||
| int | maxGaussians = -1 | |||
| ) |
This constructor will merge two models (it doesn't train them, use train for that after setting the training data setTrainingData() with a guestID!) THIS IMPLEMENTATION DOES ONLY MERGE THE FIRST CONTEXT OF SIL PHONES!!!
References channelInfoBlock, decision_Matrix, PhoneModel::dimensions, ModelStats::frameMeanLikelihood, guestTrainingLabel, PhoneModel::isSil, ModelStats::isSil, ModelStats::likelihood, FastMath::log(), ModelStats::maxNrOfContexts, maxNrOfGaussians(), PhoneModel::mixtureSetData, ModelStats::name, MixGaussian::normalizeWeights(), ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, FeaturePoolInfo::numberOfChannels, MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, PhoneModel::timeStamp, trainingLabel, trainingPool, trainingSegment, trainSilMax, trainSilP, trainWithoutBorders, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.

| TrainPhoneModel::TrainPhoneModel | ( | TrainPhoneModel * | model1, | |
| TrainPhoneModel * | model2, | |||
| double | rate | |||
| ) |
This constructor will merge two models (it doesn't train them, use train for that after setting the training data setTrainingData() with a guestID!) THIS IMPLEMENTATION DOES ONLY MERGE THE FIRST CONTEXT OF SIL PHONES!!! The number of gaussians in the models must be the same! In fact, it only works for models that are adapted from the same UBM!!!
References channelInfoBlock, decision_Matrix, PhoneModel::dimensions, ModelStats::frameMeanLikelihood, guestTrainingLabel, ModelStats::isSil, PhoneModel::isSil, ModelStats::likelihood, ModelStats::maxNrOfContexts, PhoneModel::mixtureSetData, ModelStats::name, ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, FeaturePoolInfo::numberOfChannels, MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, PhoneModel::timeStamp, trainingLabel, trainingPool, trainingSegment, trainSilMax, trainSilP, trainWithoutBorders, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.
| TrainPhoneModel::TrainPhoneModel | ( | TrainPhoneModel * | org, | |
| int | shiftLeftRight = 0 | |||
| ) |
The constructor copies the settings of the original TrainPhoneModel. This constructor is used for creating clustered-based acoustic models.
References channelInfoBlock, decision_Matrix, PhoneModel::dimensions, ModelStats::frameMeanLikelihood, guestTrainingLabel, ModelStats::isSil, PhoneModel::isSil, ModelStats::likelihood, ModelStats::maxNrOfContexts, PhoneModel::mixtureSetData, ModelStats::name, ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, FeaturePoolInfo::numberOfChannels, MixGaussian::shiftBestGaussian(), MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, PhoneModel::timeStamp, totalLength, trainingLabel, trainingPool, trainingSegment, trainSilMax, trainSilP, trainWithoutBorders, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.
| TrainPhoneModel::TrainPhoneModel | ( | FILE * | inFile, | |
| int | dim, | |||
| FeaturePoolInfo * | infoBlock = NULL | |||
| ) |
The constructor only initialises some variables. Not very interesting. The parameters are only added to make inherentece possible with the PhoneModel class.
References channelInfoBlock, decision_Matrix, PhoneModel::dimensions, ModelStats::frameMeanLikelihood, WriteFileLittleBigEndian::freadEndianSafe(), guestTrainingLabel, PhoneModel::isSil, ModelStats::isSil, ModelStats::likelihood, ModelStats::maxNrOfContexts, PhoneModel::mixtureSetData, ModelStats::name, ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, FeaturePoolInfo::numberOfChannels, PhoneModel::silRinglastPos, MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, PhoneModel::timeStamp, trainingLabel, trainingPool, trainingSegment, trainSilMax, trainSilP, trainWithoutBorders, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.

| TrainPhoneModel::~TrainPhoneModel | ( | ) |
The destructor is responsible for deleting the entire training pool.
Member Function Documentation
| void TrainPhoneModel::adapt_setAcTrain | ( | int | useLabel = -1, |
|
| int | useSegmentation = -1, |
|||
| FeaturePool * | usePool = NULL | |||
| ) |
Performs the adaptation training-run. This run will set all acumulators. You can only use other segments/labels/pools for sil models!
References PhoneModel::adapt_setAcumulators(), baumWelch(), PhoneModel::isSil, trainingLabel, trainingPool, and trainingSegment.
Referenced by ShoutPrepareAdapt::ShoutPrepareAdapt().
| void TrainPhoneModel::addCountedGaussians | ( | TrainPhoneModel * | source, | |
| int | nmbr | |||
| ) |
Add the best nmbr gaussians from the model source to this model. The best gaussians are determined during earlier counting by count(). (mixtureset 0, we expect this model to be SIL without context (used by Train_Speaker_Segmenter).
References MixGaussian::addCountedGaussians(), PhoneModel::mixtureSetData, and MixtureSet::state.
| void TrainPhoneModel::addGaussian | ( | Vector * | v | ) |
References MixGaussian::addGaussian(), PhoneModel::mixtureSetData, and MixtureSet::state.

| void TrainPhoneModel::appendSAT | ( | FILE * | outFile | ) |
Load training parameters of a model from disc.
References MixGaussian::appendSAT(), PhoneModel::mixtureSetData, ModelStats::nrOfContexts, MixtureSet::state, and PhoneModel::statistics.
Referenced by ShoutTrainFinishSAT::ShoutTrainFinishSAT().
| double TrainPhoneModel::baumWelch | ( | int | trainWhat, | |
| PhoneModel * | doSat = NULL | |||
| ) | [protected] |
This method has the same function as the method baumWelch(), to train the acoustic models. The algorithm used in this case is Viterbi. the method baumWelch() uses Baum-Welch.
This method uses the viterbi algorithm on all training samples from the pool. The total likelihood (the product of all likelihoods) is returned. The heigher this value, the better the training samples match the HMM. When the train parameter is set to true, the number of transitions into each state are stored and the MixGaussian::train() methods are called. The transition statistics are used to determine new state transition values and MixGaussian::trainFinish() is called to finish the state likelihood training.
The Baum-Welch algorithm used in this method is as follows: For every observation (in one training sample), all state transition into each state are calculated. This is done in a Forward- and Backward pass. The probability of each path is calculated. The transition weights are calculated according the these probabilities by counting the number of transitions into a state and the number of transitions into that state using a specific route (multiplied with the path probability). When all samples are handled, those two numbers are devided, and the transition chance is the result. The state likelihoods are trained with the observations from a specific path that are mapped onto a state with the weight of the path probability. For the procedure to calculate the state likelihoods out of these observation sequences, see the TrainMixGaussian::train() method.
Literature: the HTK-BOOK, page 130-132.
References ModelStats::frameMeanLikelihood, FeaturePool::getCurSegmentLen(), FeaturePool::getCurSegmentVector(), FeaturePool::getFirstVectorFirstSegment(), FeaturePool::getFirstVectorNextSegment(), MixGaussian::getP(), FeaturePool::getSegmentID(), FastMath::log(), PhoneModel::mixtureSetData, ModelStats::nrOfContexts, MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, MixGaussian::train(), MixGaussian::trainFinish(), trainingLabel, trainingPool, trainingSegment, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.
Referenced by adapt_setAcTrain(), and train().
| void TrainPhoneModel::count | ( | Vector * | observation | ) |
Counts the importance of each gaussian in the model given the feature Vector observation. (mixtureset 0, we expect this model to be SIL without context (used by Train_Speaker_Segmenter).
References MixGaussian::count(), PhoneModel::mixtureSetData, and MixtureSet::state.
Referenced by train().

| void TrainPhoneModel::doNotuseBordersForTraining | ( | bool | useBordersNot | ) |
- Todo:
- docs
References trainWithoutBorders.
Referenced by Train_Segmenter::getOverlap(), Train_Segmenter::loadClusters(), and Train_Segmenter::Train_Segmenter().
| void TrainPhoneModel::fillDistanceArray | ( | int * | distA | ) |
Fills the distance array: an array of size numberOfGaussians (mixtureSetData[0]). The two most distant gaussians are in the first and last spot. The others are sorted in between.
References MixGaussian::fillDistanceArray(), PhoneModel::mixtureSetData, and MixtureSet::state.

| double TrainPhoneModel::finishSAT | ( | ) |
Finish the training for SAT
References PhoneModel::mixtureSetData, ModelStats::nrOfContexts, MixtureSet::state, PhoneModel::statistics, and MixGaussian::trainFinish().
Referenced by ShoutTrainFinishSAT::ShoutTrainFinishSAT().
| double TrainPhoneModel::getClusterP | ( | Vector * | observation | ) |
Returns the probability of the mixtureSet 0 on the input vector.
References MixGaussian::getP(), PhoneModel::mixtureSetData, and MixtureSet::state.
| double TrainPhoneModel::getCoSim | ( | TrainPhoneModel * | t1, | |
| TrainPhoneModel * | t2 | |||
| ) |
References MixGaussian::getCoSim(), PhoneModel::mixtureSetData, and MixtureSet::state.
| int TrainPhoneModel::getDominantGaussian | ( | ) |
Determines the dominant Gaussian in the model...
References MixGaussian::getBestCount(), PhoneModel::mixtureSetData, and MixtureSet::state.

| double TrainPhoneModel::getKLDistance | ( | TrainPhoneModel * | t2 | ) |
References MixGaussian::getKLDistance(), PhoneModel::mixtureSetData, and MixtureSet::state.
Referenced by ShoutPrepareAdapt::ShoutPrepareAdapt().

| double TrainPhoneModel::getNormDistance | ( | ) |
References MixGaussian::getNormDistance(), PhoneModel::mixtureSetData, and MixtureSet::state.

| double TrainPhoneModel::getSilP | ( | int | useLabel, | |
| int | useSegmentation, | |||
| FeaturePool * | usePool | |||
| ) | [protected] |
References FeaturePool::getFirstVectorFirstSegment(), FeaturePool::getFirstVectorNextSegment(), MixGaussian::getLogP(), FeaturePool::getNextVector(), FeaturePool::getSegmentID(), PhoneModel::mixtureSetData, MixtureSet::state, PhoneModel::stateMix_1, and testP.
Referenced by getTrainSilP().
| double TrainPhoneModel::getTrainSilP | ( | int | useLabel = -1, |
|
| int | useSegmentation = -1, |
|||
| FeaturePool * | usePool = NULL | |||
| ) |
Used by the train() method to calculate the current score if the phone is a SIL phone. Effectively the score is the MixGaussian probability (MixGaussian::getP()) of all training samples. It is possible to use an alternative training pool to calculate the score.
References ModelStats::frameMeanLikelihood, getSilP(), PhoneModel::statistics, trainingLabel, trainingPool, and trainingSegment.
Referenced by Train_Segmenter::getMergeModelScore(), Train_Segmenter::getOverlap(), Adapt_Segmenter::proceedMerge(), ShoutSegment::ShoutSegment(), thread_train_cluster(), train(), and Train_Segmenter::trainModel().
| int TrainPhoneModel::maxNrOfGaussians | ( | ) |
This method retrieves the number of gausians of each state and returns the maximum value.
References MixGaussian::getNumberOfGaussians(), PhoneModel::mixtureSetData, ModelStats::nrOfContexts, MixtureSet::state, and PhoneModel::statistics.
Referenced by setMaxGaussians(), train(), Train_Segmenter::trainClusters(), and TrainPhoneModel().

| void TrainPhoneModel::moveModelGaussians | ( | TrainPhoneModel * | model, | |
| double | factor | |||
| ) |
- Todo:
- docs
References PhoneModel::mixtureSetData, MixGaussian::moveModelGaussians(), and MixtureSet::state.

| void TrainPhoneModel::normalize | ( | ) |
References Gaussian::getMean(), Vector::getValue(), Gaussian::getVariance(), PhoneModel::mixtureSetData, ModelStats::nrOfContexts, Vector::setValue(), PhoneModel::statistics, Gaussian::train(), Gaussian::trainFinish(), and MixtureSet::transitionP_toNext.
| bool TrainPhoneModel::readModel | ( | FILE * | inFile | ) |
readModel reads a model from disc. Especially needed for MultiMixGaussian PDFs
References channelInfoBlock, PhoneModel::dimensions, ModelStats::frameMeanLikelihood, WriteFileLittleBigEndian::freadEndianSafe(), PhoneModel::isSil, ModelStats::isSil, ModelStats::likelihood, ModelStats::maxNrOfContexts, PhoneModel::mixtureSetData, ModelStats::name, ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, FeaturePoolInfo::numberOfChannels, MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, and PhoneModel::statistics.
Referenced by Train_Segmenter::loadClusters(), and Train_Segmenter::Train_Segmenter().

| void TrainPhoneModel::setDecisionMatrix | ( | int | numberOfModels, | |
| int | numberOfRules, | |||
| int * | dMatrix | |||
| ) |
This method will set a new decision-rule matrix. Each row in this matrix contains all phones that are part of a particular tree-based clustering rule.
References decision_Matrix, decision_numberOfModels, and decision_numberOfRules.
Referenced by ShoutTrainModel::ShoutTrainModel().
| void TrainPhoneModel::setMaxGaussians | ( | int | maxGaussians | ) |
Set the maximum number of gaussians...
References PhoneModel::isSil, maxNrOfGaussians(), PhoneModel::mixtureSetData, MixGaussian::normalizeWeights(), and MixtureSet::state.

| void TrainPhoneModel::setTrainingData | ( | FeaturePool * | fp, | |
| int | trainID, | |||
| int | labelID, | |||
| int | guestID = -1, |
|||
| int | tSilP = 100, |
|||
| int | tSilMax = -1 | |||
| ) |
The FeaturePool contains all training data! Deleting the training pool after it has no more use, is the responsability of the user, because one pool maybe used by multiple models!
References guestTrainingLabel, trainingLabel, trainingPool, trainingSegment, trainSilMax, and trainSilP.
Referenced by Adapt_AM::Adapt_AM(), ShoutSegment::doSAD_noGarbage(), Train_Segmenter::getMergeModelScore(), Train_Segmenter::getOverlap(), Train_Segmenter::loadClusters(), Train_Segmenter::mergeModels(), Adapt_Segmenter::proceedMerge(), ShoutPrepareAdapt::ShoutPrepareAdapt(), ShoutSegment::ShoutSegment(), ShoutTrainModel::ShoutTrainModel(), Train_Segmenter::Train_Segmenter(), Train_Segmenter::trainIteration(), and Train_Segmenter::trainModel().
| void TrainPhoneModel::startCount | ( | ) |
Starts a counting run for determining the most important gaussians of this model (mixtureset 0, we expect this model to be SIL without context (used by Train_Speaker_Segmenter).
References PhoneModel::mixtureSetData, MixGaussian::startCount(), and MixtureSet::state.

| void TrainPhoneModel::stopCount | ( | ) |
Stops the counting run for determining the most important gaussians of this model (mixtureset 0, we expect this model to be SIL without context (used by Train_Speaker_Segmenter).
References PhoneModel::mixtureSetData, MixtureSet::state, and MixGaussian::stopCount().

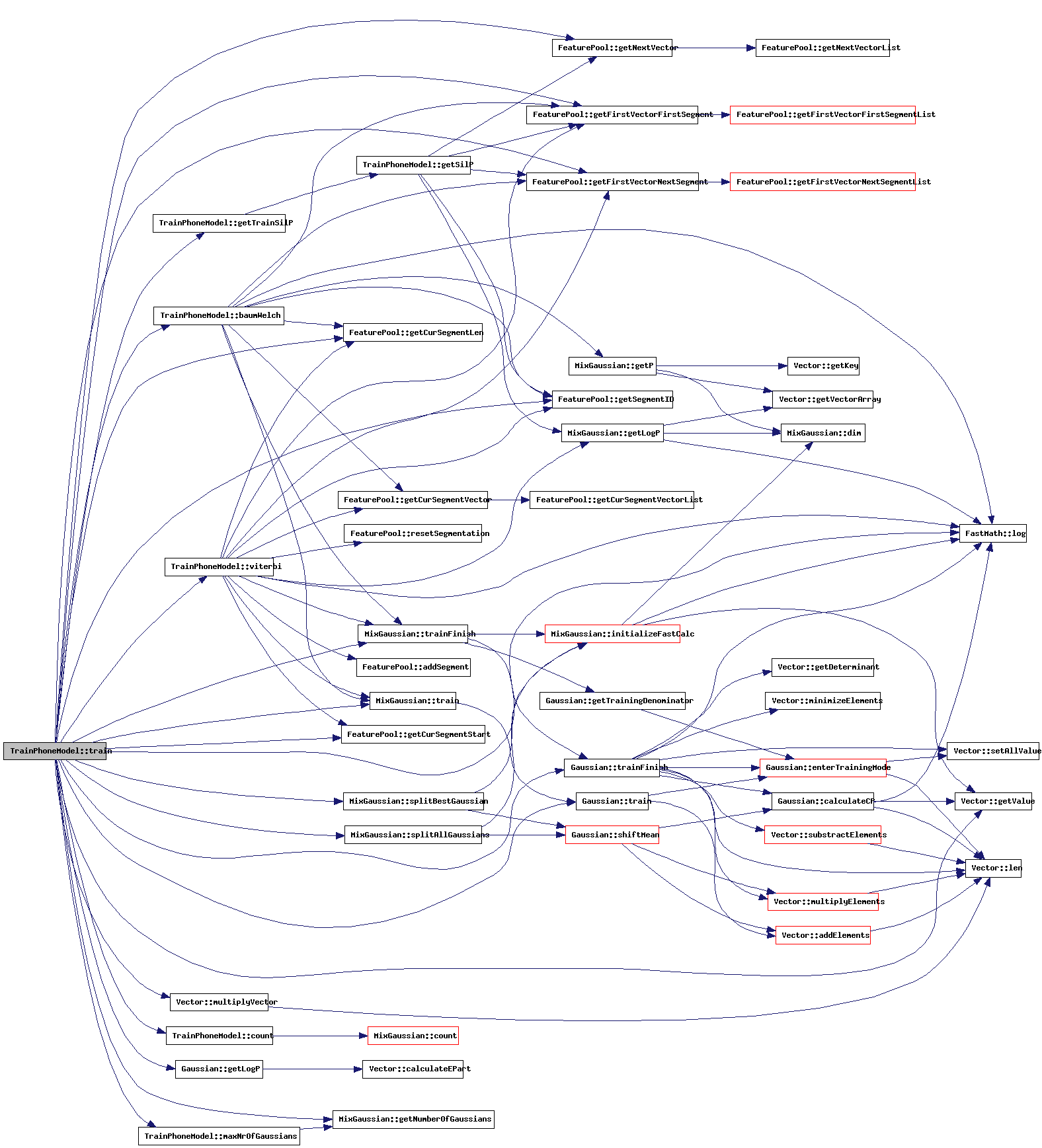
| double TrainPhoneModel::train | ( | int | maxGaussians, | |
| bool | isS, | |||
| bool | neverPrune = false, |
|||
| Vector ** | trainDiscr = NULL, |
|||
| Vector * | trainDiscrMask = NULL, |
|||
| PhoneModel * | doSat = NULL, |
|||
| bool | doFastTraining = false | |||
| ) |
This method is responsible for the training iteration. First it checks if the HMM is a SIL HMM or a regular one. SIL HMMs only have one state and only this one state is trained. Apart from this difference, both types of HMMs are trained as follows:
First it is checked if an existing HMM is already loaded. If not, an empty HMM is created. Then, in a loop, the system calculates the total likelihood on all training samples by calling viterbi() with its training parameter set to true. When the result is more than MINIMUM_TRAIN_IMPROVEMENT better than the last result, another viterbi iteration is performed. Otherwise, it is checked if it is allowed to add more gaussians to each state-> This is allowed as long as during the previous iterations, the number of gaussians has not been reduced (it is possible that a gaussian is pruned, when not enough training samples represent it) and the maximum number of gaussians has not yet been reached. The MixGaussian::splitBestGaussian() method is used to split the gaussians. After splitting, the entire procedure is repeated. If splitting was not permitted, the training run has finished.
When the training run is finished, the training sample pool is deleted. This means that it is not possible to train the system again, without providing new samples (but who would want to?)
References baumWelch(), count(), SegmentationAdmin::curSeg, decision_Matrix, decision_numberOfModels, decision_numberOfRules, SegmentationList::firstFrame, FeaturePool::getCurSegmentLen(), FeaturePool::getCurSegmentStart(), FeaturePool::getFirstVectorFirstSegment(), FeaturePool::getFirstVectorNextSegment(), Gaussian::getLogP(), FeaturePool::getNextVector(), MixGaussian::getNumberOfGaussians(), FeaturePool::getSegmentID(), getTrainSilP(), Vector::getValue(), guestTrainingLabel, SegmentationList::ID, ModelStats::isSil, PhoneModel::isSil, SegmentationList::lastFrame, ModelStats::likelihood, FastMath::log(), ModelStats::maxNrOfContexts, maxNrOfGaussians(), MINPASSES, PhoneModel::mixtureSetData, Vector::multiplyVector(), ModelStats::name, SegmentationList::next, ModelStats::nrOfContexts, ModelStats::nrOfGaussians, ModelStats::nrOfTrainOcc, SegmentationAdmin::prevSeg, MixGaussian::splitAllGaussians(), MixGaussian::splitBestGaussian(), MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, Gaussian::train(), MixGaussian::train(), Gaussian::trainFinish(), MixGaussian::trainFinish(), trainingLabel, trainingPool, trainingSegment, trainSilMax, trainSilP, trainWithoutBorders, MixtureSet::transitionP_toNext, MixtureSet::transitionP_toSelf, and viterbi().
Referenced by Train_Segmenter::getMergeModelScore(), Train_Segmenter::getOverlap(), Train_Segmenter::mergeModels(), Adapt_Segmenter::proceedMerge(), ShoutPrepareAdapt::ShoutPrepareAdapt(), ShoutSegment::ShoutSegment(), ShoutTrainModel::ShoutTrainModel(), thread_train(), thread_train_cluster(), Train_Segmenter::trainModel(), and ShoutSegment::trainModel().
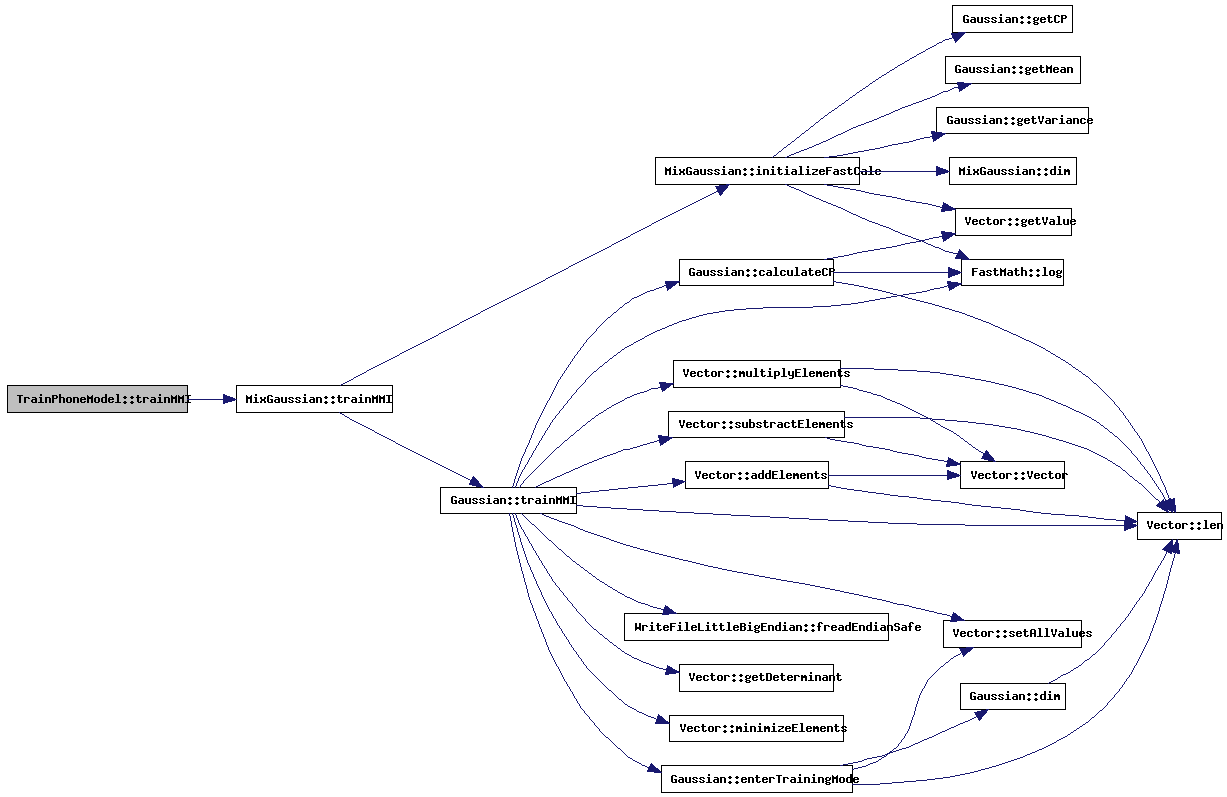
| void TrainPhoneModel::trainMMI | ( | FILE * | fileEnum, | |
| FILE * | fileDenom | |||
| ) |
This method will read training accumulators from file and perform MMI training
References PhoneModel::mixtureSetData, ModelStats::nrOfContexts, MixtureSet::state, PhoneModel::statistics, and MixGaussian::trainMMI().
Referenced by ShoutTrainMMI::ShoutTrainMMI().
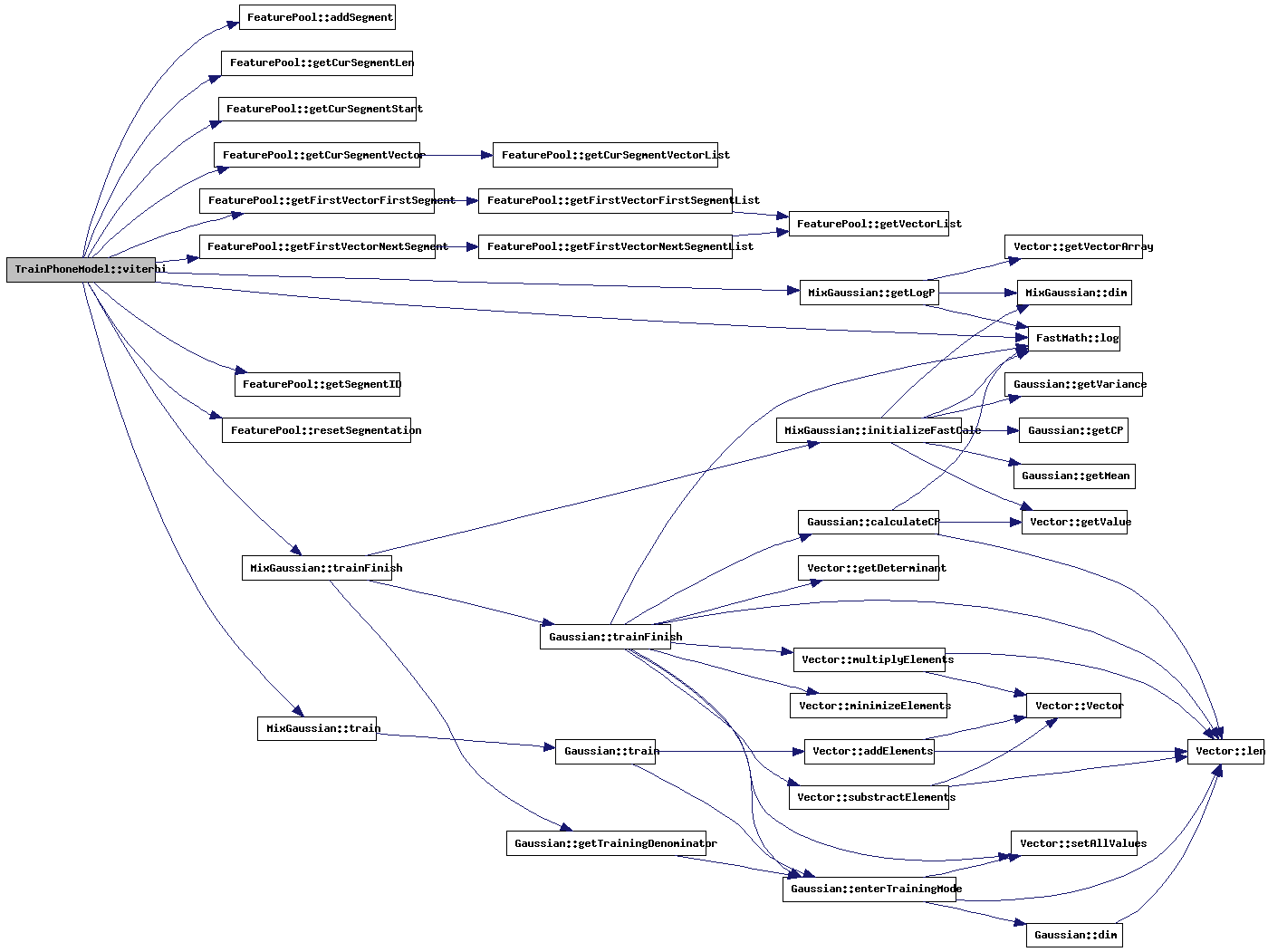
| double TrainPhoneModel::viterbi | ( | int | trainWhat | ) | [protected] |
This method has the same function as the method viterbi(), to train the acoustic models. The algorithm used in this case is Baum-Welch. the method viterbi() uses Viterbi.
This method uses the Baum-Welch algorithm on all training samples from the pool. The total likelihood (the product of all likelihoods) is returned. The heigher this value, the better the training samples match the HMM. When the train parameter is set to true, the number of transitions into each state are stored and the MixGaussian::train() methods are called. The transition statistics are used to determine new state transition values and MixGaussian::trainFinish() is called to finish the state likelihood training.
The viterbi algorithm used in this method is as follows: For every observation (in one training sample), the highest probable state transition into each state is calculated. Basically, this means comparing between two transitions (for example, state 2 may get input from state 1 or from itself). The transition choosen is stored in the variable transPath. After all observations are handled, the best path is calculated by starting at the final state at time observationLength and 'walking' back in the transPath matrix. The transition weights are calculated directly from the 'best path' transitions by counting the number of transitions into a state and the number of transitions into that state using a specific route. When all samples are handled, those two numbers are devided, and the transition chance is the result. The state likelihoods are trained with those observations from the best path that are mapped onto a state-> For the procedure to calculate the state likelihoods out of these observation sequences, see the TrainMixGaussian::train() method.
Literature: Frederick Jelinek, "Statistical Methods for Speech Recognition": page 22 for the viterbi training procedure and page 30 for transition weight calculation.
References FeaturePool::addSegment(), ModelStats::frameMeanLikelihood, FeaturePool::getCurSegmentLen(), FeaturePool::getCurSegmentStart(), FeaturePool::getCurSegmentVector(), FeaturePool::getFirstVectorFirstSegment(), FeaturePool::getFirstVectorNextSegment(), MixGaussian::getLogP(), FeaturePool::getSegmentID(), FastMath::log(), PhoneModel::mixtureSetData, ModelStats::nrOfContexts, ModelStats::nrOfTrainOcc, FeaturePool::resetSegmentation(), MixtureSet::state, PhoneModel::stateMix_1, PhoneModel::stateMix_2, PhoneModel::stateMix_3, PhoneModel::statistics, MixGaussian::train(), MixGaussian::trainFinish(), trainingLabel, trainingPool, trainingSegment, MixtureSet::transitionP_toNext, and MixtureSet::transitionP_toSelf.
Referenced by train().
| void TrainPhoneModel::writeSAT | ( | FILE * | outFile | ) |
WriteSAT writes the training parameters of a model to disc. These data will later be used by the SAT training application.
References PhoneModel::mixtureSetData, ModelStats::nrOfContexts, MixtureSet::state, PhoneModel::statistics, and MixGaussian::storeSAT().
Referenced by ShoutTrainModel::ShoutTrainModel().

Member Data Documentation
FeaturePoolInfo* TrainPhoneModel::channelInfoBlock [protected] |
Referenced by readModel(), and TrainPhoneModel().
int* TrainPhoneModel::decision_Matrix [protected] |
Referenced by setDecisionMatrix(), train(), and TrainPhoneModel().
int TrainPhoneModel::decision_numberOfModels [protected] |
Referenced by setDecisionMatrix(), and train().
int TrainPhoneModel::decision_numberOfRules [protected] |
Referenced by setDecisionMatrix(), and train().
int TrainPhoneModel::guestTrainingLabel [protected] |
Referenced by setTrainingData(), train(), and TrainPhoneModel().
int TrainPhoneModel::totalLength [protected] |
Referenced by TrainPhoneModel().
int TrainPhoneModel::trainingLabel [protected] |
Referenced by adapt_setAcTrain(), baumWelch(), getTrainSilP(), setTrainingData(), train(), TrainPhoneModel(), and viterbi().
FeaturePool* TrainPhoneModel::trainingPool [protected] |
Referenced by adapt_setAcTrain(), baumWelch(), getTrainSilP(), setTrainingData(), train(), TrainPhoneModel(), and viterbi().
int TrainPhoneModel::trainingSegment [protected] |
Referenced by adapt_setAcTrain(), baumWelch(), getTrainSilP(), setTrainingData(), train(), TrainPhoneModel(), and viterbi().
int TrainPhoneModel::trainSilMax [protected] |
Referenced by setTrainingData(), train(), and TrainPhoneModel().
int TrainPhoneModel::trainSilP [protected] |
Referenced by setTrainingData(), train(), and TrainPhoneModel().
bool TrainPhoneModel::trainWithoutBorders [protected] |
Referenced by doNotuseBordersForTraining(), train(), and TrainPhoneModel().